4 Metodi Semplici per Riconoscere il Testo nei PDF

Sommario :
L’articolo descrive 4 modi per riconoscere il testo nei PDF, sottolineando l’importanza dell’OCR (riconoscimento ottico dei caratteri) per convertire i PDF basati su immagini in PDF basati su testo per una più facile modifica e interazione.
Indice

Come Riconoscere il Testo nei PDF
Riconoscere il testo nei PDF, tipicamente tramite la tecnologia OCR, è cruciale per trasformare i documenti basati su immagini in formati modificabili e ricercabili. Questo processo rende i documenti più facili da accedere. Permette anche di estrarre e modificare i dati più facilmente.
Inoltre, aiuta a memorizzare meglio le informazioni digitali e a trovarle facilmente. Questo è davvero importante per le aziende, i ricercatori e gli educatori.
Come Riconoscere Testo in un PDF Scansionato Gratis con PDFgear
PDFgear è uno strumento OCR (Optical Character Recognition) gratuito progettato per rendere modificabili i PDF scansionati o per estrarre testo dai documenti che non consentono la selezione del testo. Offre una funzione di OCR area per estrarre rapidamente il testo da aree specifiche di un PDF.
A differenza di molti altri editor PDF che mettono le funzionalità OCR dietro un paywall, PDFgear offre capacità OCR accurate e multilingue gratuitamente. Ecco come utilizzare PDFgear per riconoscere il testo in un PDF scansionato:
Passo 1. Aggiungi il File PDF a PDFgear
Prima di tutto, scarica e installa PDFgear su Windows o Mac. Avvia PDFgear sul tuo computer.
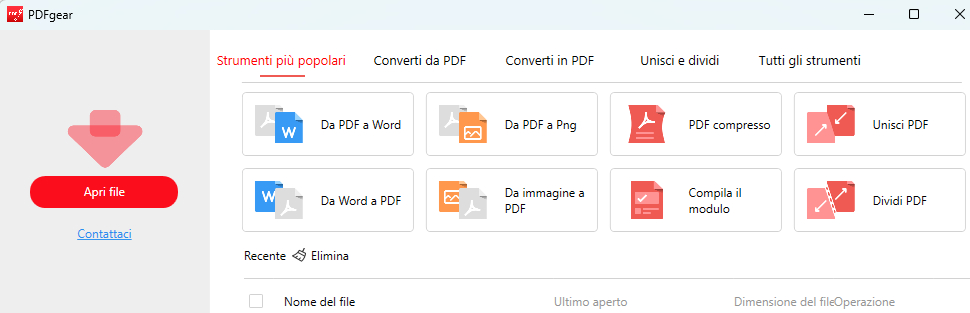
Apri un PDF con PDFgear
Clicca su “Apri File“. Scegli il PDF da cui vuoi estrarre il testo e clicca su “Apri“.
Passo 2. Seleziona la Funzione OCR
Cerca la funzione “OCR” nella scheda “Pagina iniziale”. Clicca su “OCR” per attivarla.
Usa il mouse per evidenziare il testo che vuoi estrarre. Rilascia il pulsante del mouse una volta selezionato il testo.
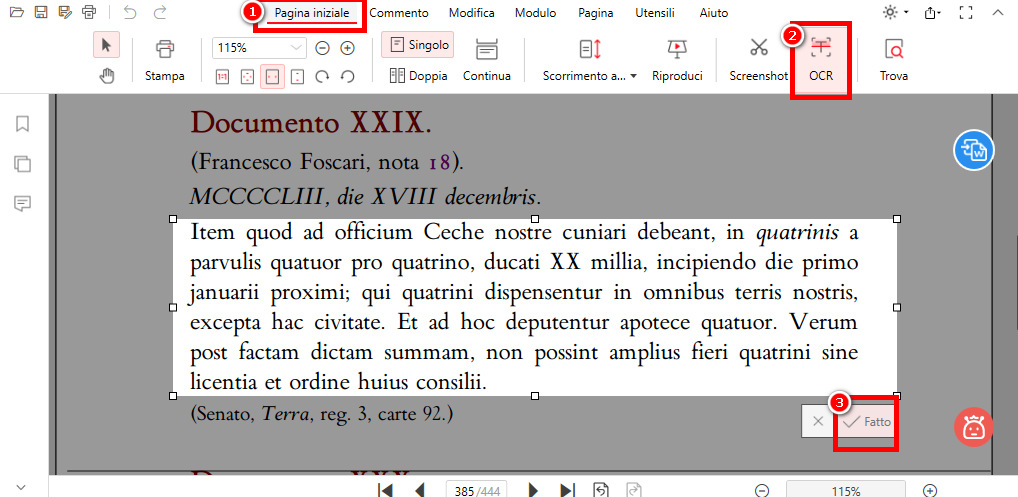
Esegui OCR su un PDF Scansionato
Passo 3. Salva o Estrai la Sezione Selezionata
Clicca su “Fatto” per elaborare. Si aprirà una finestra di dialogo per copiare o salvare il testo selezionato e per scegliere la lingua del documento originale per risultati migliori.
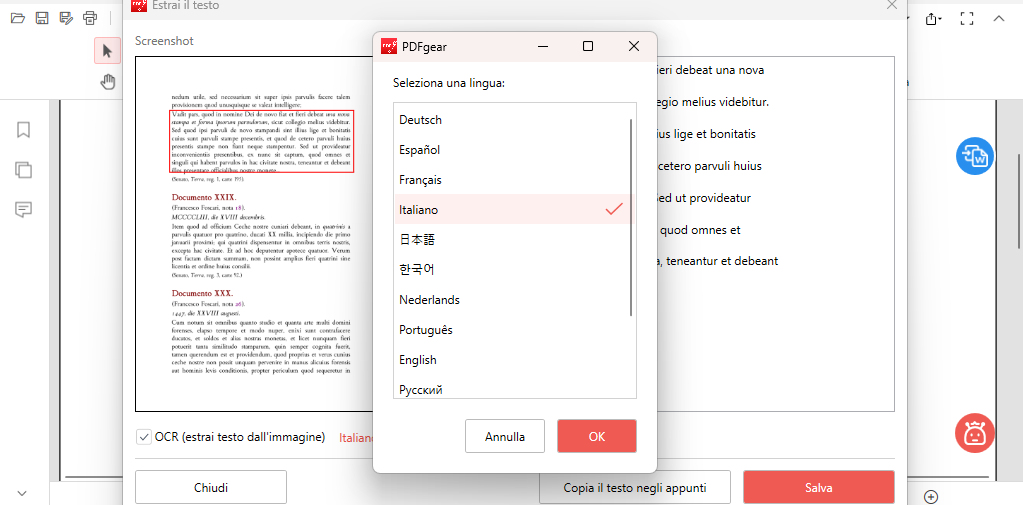
Scegli la Lingua di Estrazione del Testo
Puoi copiare il testo negli appunti o cliccare su “Salva” per salvare il file in formato TXT.
Come Riconoscere Testo in un PDF Scansionato con Adobe Acrobat
Usa la funzione OCR integrata di Adobe Acrobat. Questa funzione consente agli utenti di convertire i PDF solo immagine in documenti leggibili riconoscendo la maggior parte del testo.
Questo potente strumento può riconoscere e convertire accuratamente il testo all’interno dei PDF, offrendo opzioni per modificare, cercare e copiare il testo.
Passo 1. Apri il Tuo PDF in Adobe Acrobat Pro DC
Avvia Adobe Acrobat Pro. Apri il documento PDF in cui desideri riconoscere il testo cliccando su “File” > “Apri” e selezionando il tuo documento.
Passo 2. Accedi allo Strumento OCR
Una volta aperto il tuo PDF, cerca il pannello “Strumenti” sul lato destro della finestra.
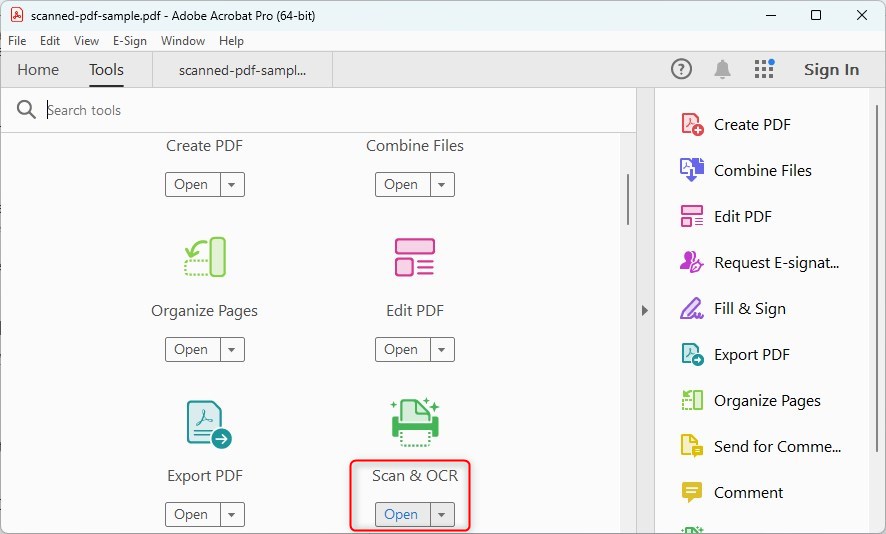
Apri lo Strumento OCR in Adobe
Scorri tra gli strumenti o cerca “Scan & OCR“. Clicca su di esso per aprire il set di strumenti OCR.
Passo 3. Riconosci il Testo
Nel pannello “Scan & OCR“, vedrai un’opzione che dice “Riconosci Testo“. Clicca su di essa.
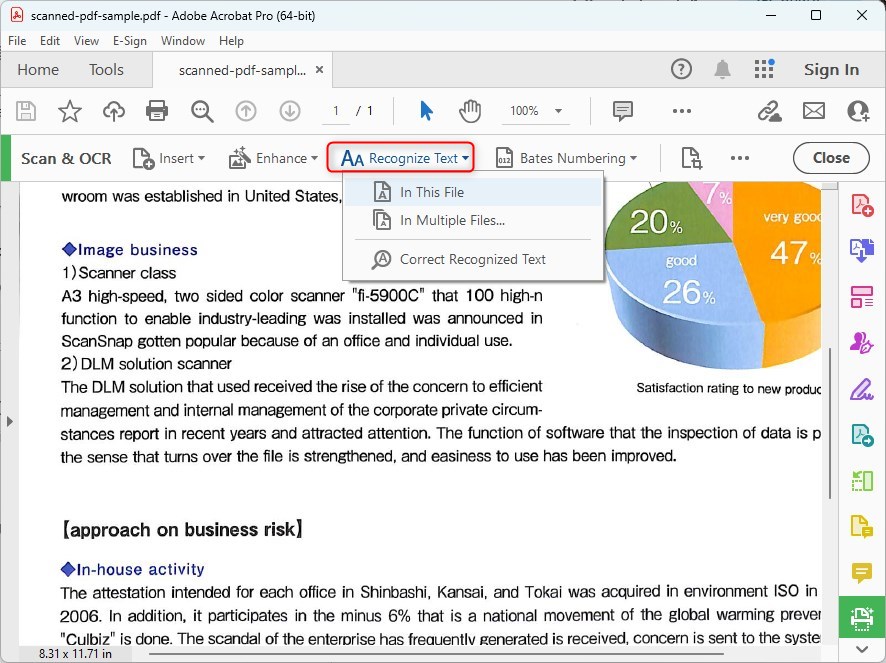
Riconosci Tutto il Testo in Adobe Acrobat DC
Ti verranno presentate due opzioni: “In Questo File” e “In Più File“. Scegli “In Questo File” per il documento che hai aperto, o “In Più File” se desideri applicare OCR a più documenti contemporaneamente.
Passo 4. Seleziona le Impostazioni OCR
Dopo aver scelto di riconoscere il testo nel tuo file/i tuoi file, dovrai selezionare la lingua del documento e decidere se vuoi riconoscere il testo in tutte le pagine o specificare un intervallo. Fai le tue selezioni di conseguenza.
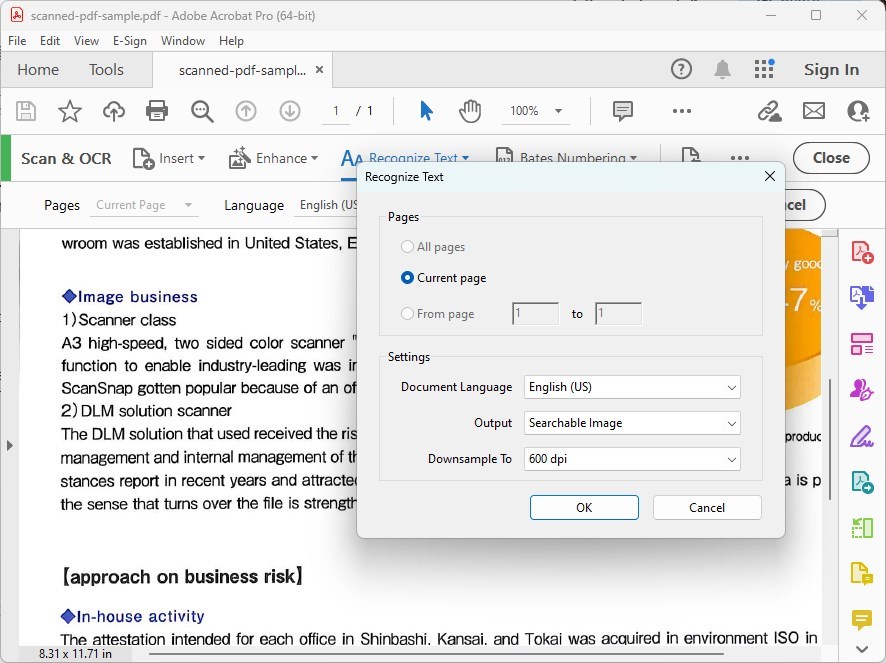
Personalizza le Impostazioni di Riconoscimento del Testo
Clicca sul pulsante “Impostazioni” per accedere ad opzioni aggiuntive, come lo stile di output (Immagine Ricercabile o Testo e Immagini Modificabili) e la risoluzione. Regola queste impostazioni in base alle tue esigenze.
Passo 5. Avvia il Processo OCR
Una volta configurate le tue impostazioni, clicca sul pulsante “Riconosci Testo” per avviare il processo OCR.
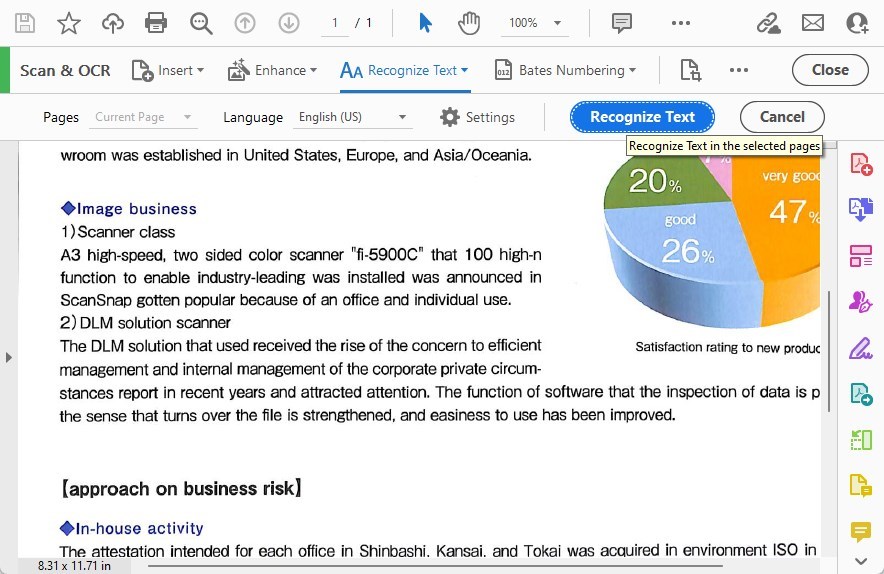
Riconosci il Testo nelle Pagine Selezionate
Adobe Acrobat inizierà a convertire il testo immagine nel tuo PDF in testo ricercabile e modificabile.
Come Riconoscere Testo nei PDF Scansionati con Google Docs
Google Docs è ampiamente accessibile e gratuito per chiunque abbia un account Google. È basato sul web, quindi puoi accedervi da qualsiasi luogo senza dover installare software specializzati.
Carica e apri il PDF in Google Docs. Google Docs ha un’opzione per convertire i file PDF (e le immagini) in testo modificabile quando carichi un file PDF come Documento Google, il che può essere particolarmente utile per conversioni rapide.
Passo 1. Accedi al tuo account Google e vai su Google Drive. Clicca sul pulsante “Nuovo” sul lato sinistro, quindi seleziona “Caricamento file“.
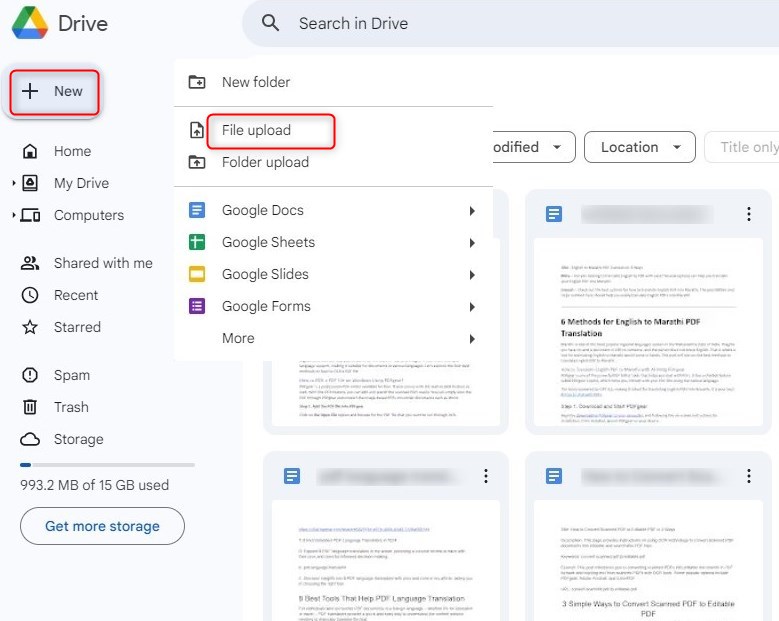
Carica un File su Google Drive
Sfoglia il tuo computer per il file PDF che vuoi convertire e selezionalo. Il file verrà quindi caricato sul tuo Google Drive.
Passo 2. Una volta completato il caricamento, individua il file PDF nel tuo Google Drive.
Fai clic con il tasto destro sul file, passa il mouse su “Apri con“, quindi seleziona “Google Docs“.
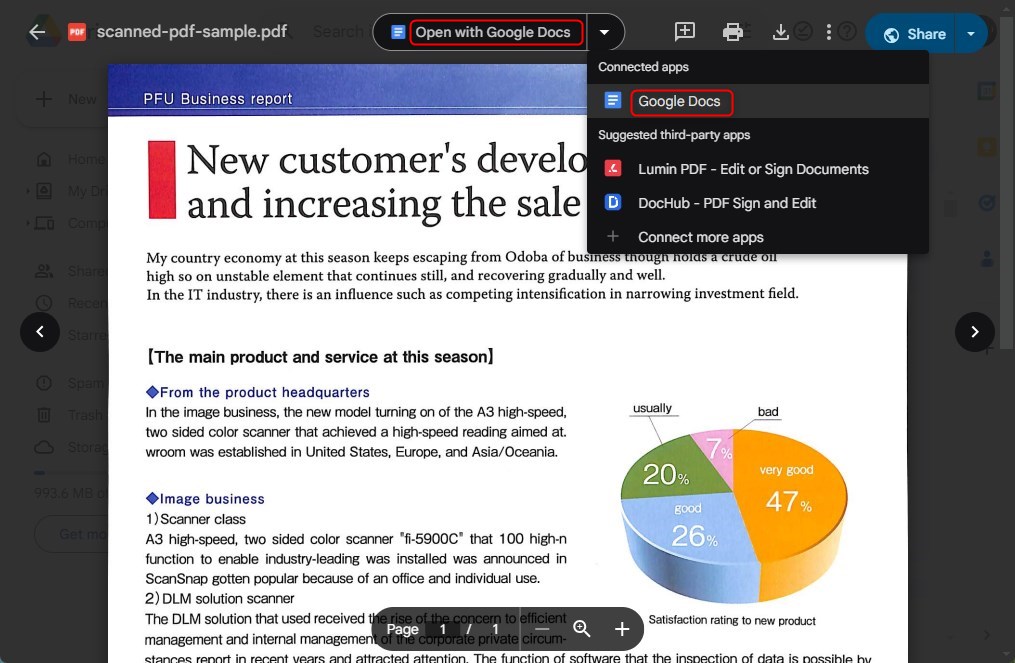
Apri un PDF Scansionato con Google Docs
Passo 3. Google Docs inizierà automaticamente il processo OCR e aprirà il documento come un nuovo file Google Docs.
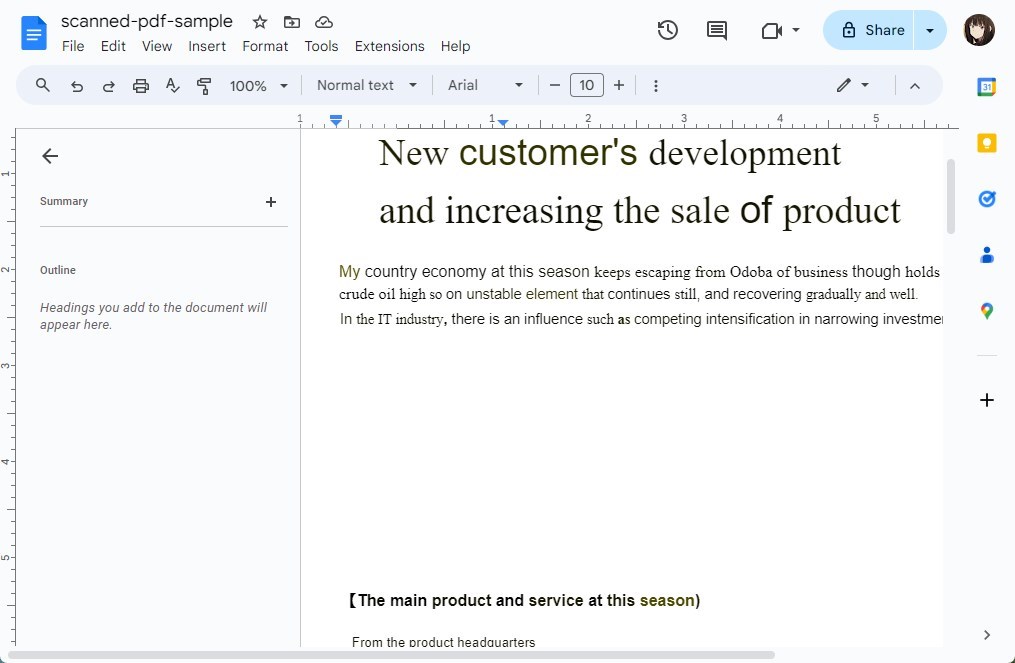
Visualizzazione di un PDF Scansionato in Google Docs
Dopo che il documento si apre in Google Docs, puoi modificare il testo secondo necessità. Il layout originale del PDF potrebbe non essere perfettamente conservato, soprattutto se il documento conteneva molte immagini o formattazione complessa.
Passo 4. Puoi salvare il documento in Google Docs, o scaricarlo in vari formati cliccando su “File” > “Scarica”, quindi scegliendo il tuo formato preferito (ad es., Microsoft Word, PDF, Testo Semplice, ecc.).
Come Utilizzare OCR per Riconoscere Testo nei PDF Online Gratis
Sejda offre un modo semplice ed efficiente per convertire scansioni PDF in testo e PDF ricercabili, oltre a estrarre testo dalle scansioni.
Questo strumento online è gratuito per documenti fino a 10 pagine o 50 MB e consente fino a 3 compiti all’ora. Per documenti più grandi, è disponibile un servizio PRO per documenti fino a 100 pagine.
Passo 1. Vai alla pagina dello strumento OCR PDF di Sejda nel tuo browser web.
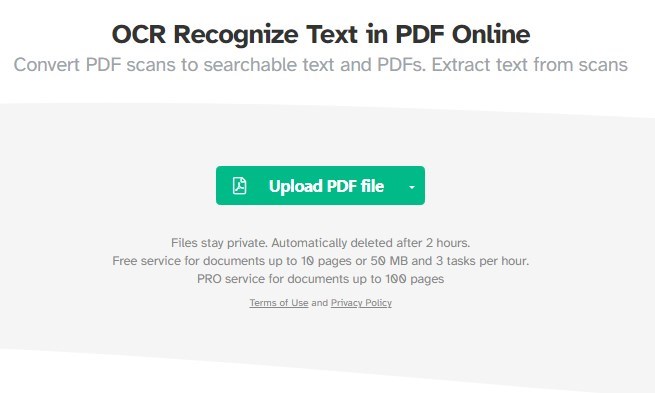
Usa lo Strumento OCR PDF di Sejda
Passo 2. Clicca su “Carica file PDF” per scegliere un PDF dal tuo computer o trascinalo sulla pagina. Puoi anche utilizzare file da Dropbox o Google Drive.
Passo 3. Seleziona la lingua del documento dal menu a tendina per migliorare l’accuratezza.
Scegli se vuoi un output PDF ricercabile o testo semplice, o entrambi.
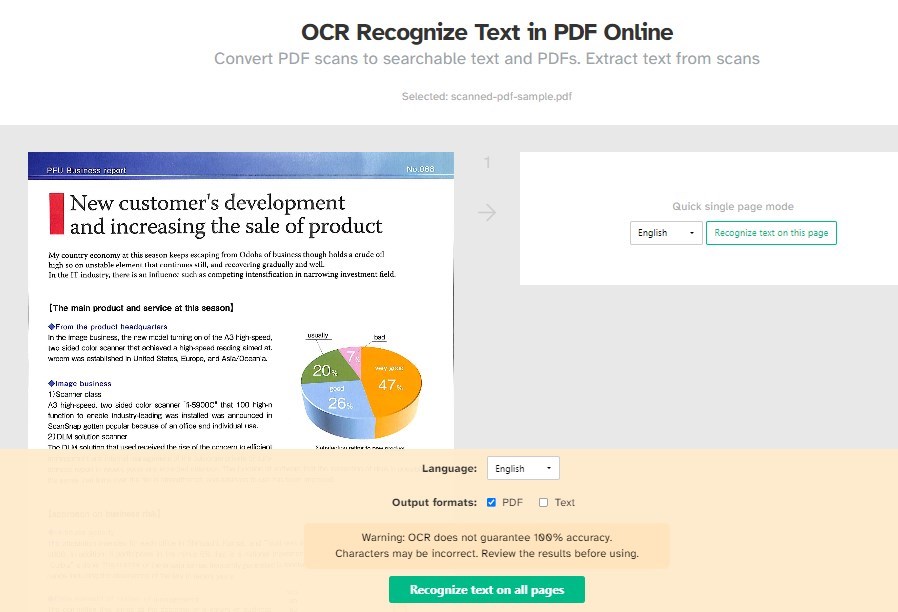
OCR Riconosci Testo in PDF Online
Passo 4. Clicca sul pulsante verde in fondo alla pagina per iniziare a riconoscere il testo. Potrebbe volerci un po’ di tempo, a seconda delle dimensioni del file.
Passo 5. Dopo che è stato completato, scarica il/i file risultante/i cliccando su “Scarica”. Puoi ottenere il PDF ricercabile o il file di testo, o entrambi separatamente se hai scelto entrambe le opzioni.
Conclusione
Per riconoscere il testo nei PDF, hai diverse opzioni. Puoi utilizzare strumenti gratuiti come PDFgear e Google Docs. C’è anche Sejda, che ha limiti sul numero di file che puoi utilizzare, e Adobe Acrobat, che richiede un pagamento.
Ogni opzione aiuta a rendere i PDF modificabili e ricercabili, soddisfacendo diverse esigenze, dalle opzioni gratuite agli strumenti professionali.