4 Métodos Simples para Reconocer Texto en PDF

Resumen :
El artículo describe 4 maneras de reconocer texto en PDFs, enfatizando la importancia del OCR (Reconocimiento Óptico de Caracteres) para convertir PDFs basados en imágenes a PDFs basados en texto para facilitar su edición e interacción.
Tabla de Contenido

Cómo Reconocer Texto en PDF
Reconocer texto en PDFs, generalmente a través de tecnología OCR, es crucial para transformar documentos basados en imágenes en formatos editables y buscables. Este proceso hace que los documentos sean más fáciles de acceder. También permite extraer y editar datos más fácilmente.
Además, ayuda a almacenar mejor la información digital y a encontrarla fácilmente. Esto es muy importante para empresas, investigadores y educadores.
Cómo Reconocer Texto en PDF Escaneado Gratis con PDFgear
PDFgear es una herramienta OCR (Reconocimiento Óptico de Caracteres) gratuita diseñada para PDFs escaneados editables o para extraer texto de documentos que no permiten la selección de texto. Ofrece una función de OCR por áreas para rápida extracción de texto de áreas específicas de un PDF.
A diferencia de muchos otros editores de PDF que colocan las funciones de OCR detrás de un muro de pago, PDFgear ofrece capacidades OCR precisas y multilingües sin costo. Aquí se explica cómo usar PDFgear para reconocer texto en un PDF escaneado:
Paso 1. Añadir el Archivo PDF a PDFgear
Primero, descargue e instale PDFgear en Windows o Mac. Inicie PDFgear en su computadora.
Abrir un PDF con PDFgear
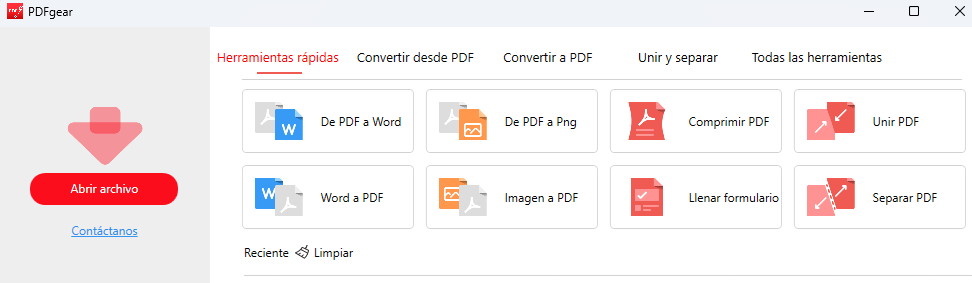
Haga clic en “Abrir Archivo“. Elija el PDF del que desea extraer texto y haga clic en “Abrir“.
Paso 2. Seleccionar la Función de OCR
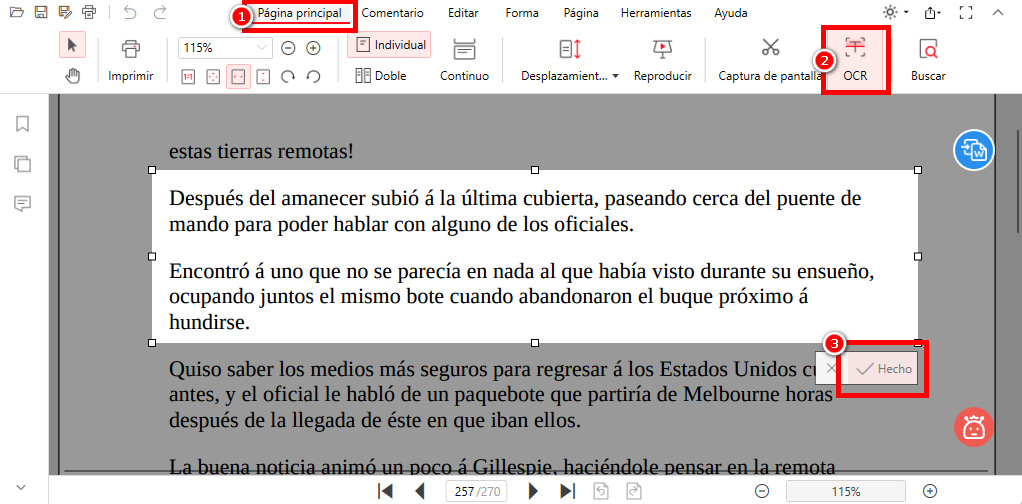
Busque la función “OCR” en la pestaña “Página principal”. Haga clic en “OCR” para activarla.
Use el ratón para resaltar el texto que desea extraer. Suelte el botón del ratón una vez seleccionado el texto.
Realizar OCR en un PDF Escaneado
Paso 3. Guardar o Extraer la Sección Seleccionada
Haga clic en “Hecho” para procesar. Se abrirá un cuadro de diálogo para copiar o guardar el texto seleccionado y elegir el idioma del documento original para mejores resultados.
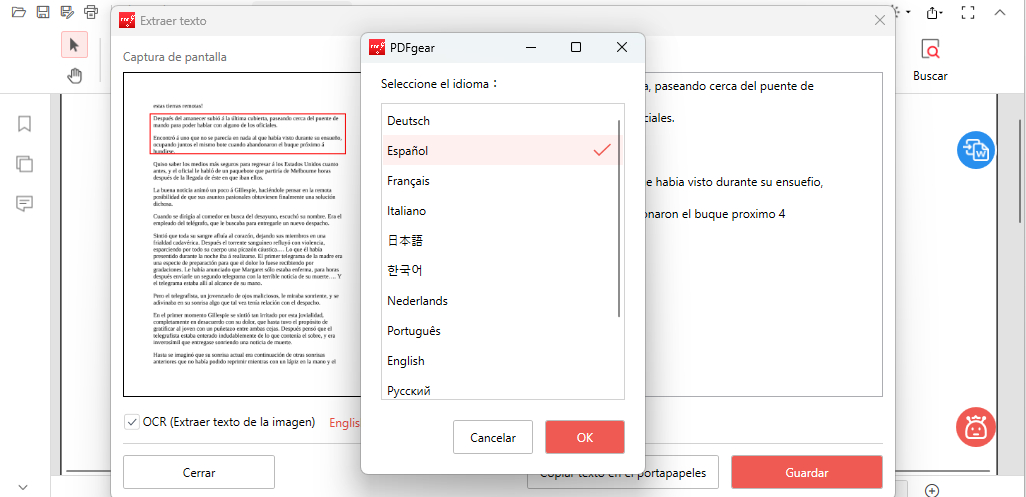
Elegir el Idioma de Extracción de Texto
Puede copiar el texto al portapapeles o hacer clic en “Guardar” para guardar el archivo en formato TXT.
Cómo Reconocer Texto en un PDF Escaneado Usando Adobe Acrobat
Use la función OCR integrada de Adobe Acrobat. Esta función permite a los usuarios convertir PDFs solo de imagen en documentos legibles reconociendo la mayor parte del texto.
Esta poderosa herramienta puede reconocer y convertir con precisión el texto dentro de los PDFs, ofreciendo opciones para editar, buscar y copiar texto.
Paso 1. Abra su PDF en Adobe Acrobat Pro DC
Inicie Adobe Acrobat Pro. Abra el documento PDF en el que desea reconocer texto haciendo clic en “Archivo” > “Abrir” y seleccionando su documento.
Paso 2. Acceder a la Herramienta de OCR
Una vez que su PDF esté abierto, busque el panel de “Herramientas” en el lado derecho de la ventana.
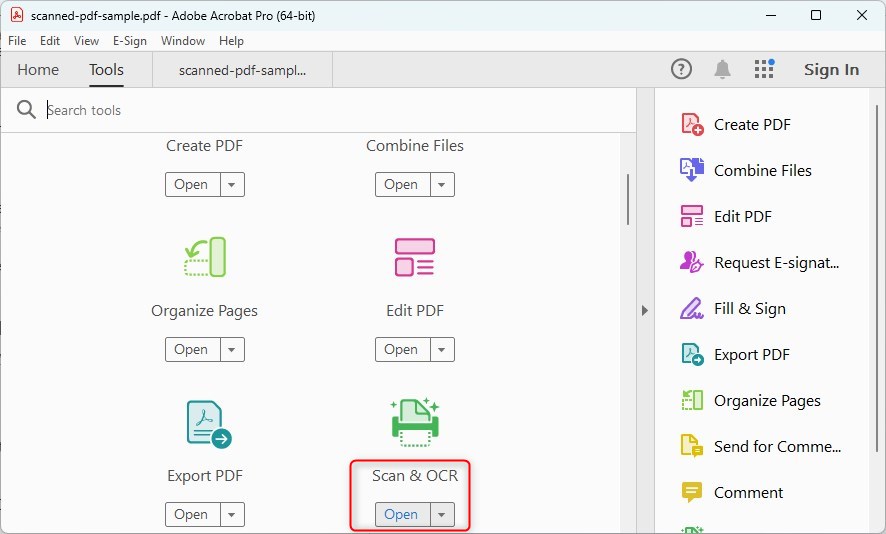
Abrir la Herramienta de OCR en Adobe
Desplácese por las herramientas o busque “Escanear & OCR“. Haga clic en él para abrir el conjunto de herramientas de OCR.
Paso 3. Reconocer Texto
En el panel de “Escanear & OCR“, verá una opción que dice “Reconocer Texto“. Haga clic en ella.
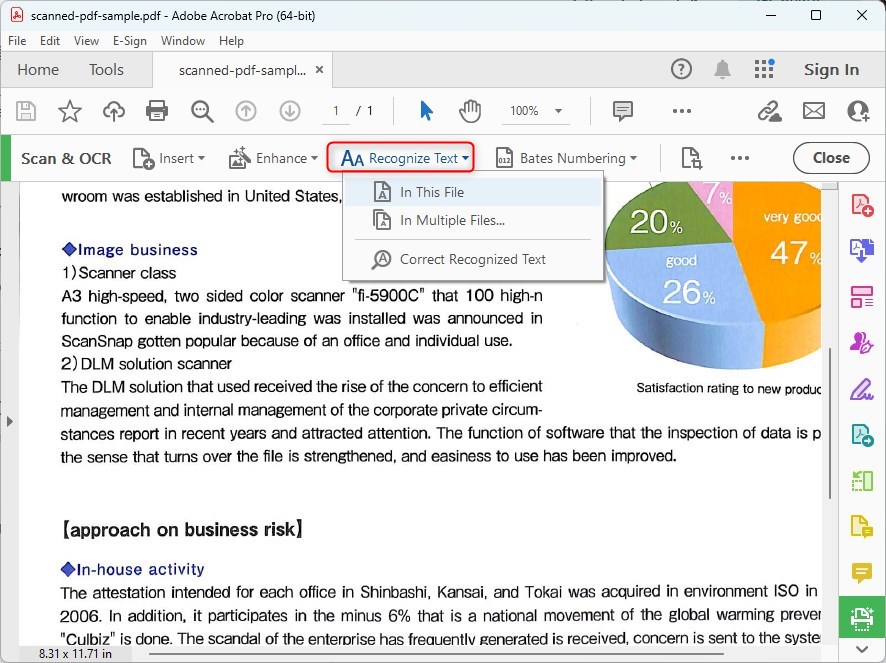
Reconocer Todo el Texto en Adobe Acrobat DC
Se le presentarán dos opciones: “En Este Archivo” y “En Múltiples Archivos“. Elija “En Este Archivo” para el documento que tiene abierto, o “En Múltiples Archivos” si desea aplicar OCR a varios documentos a la vez.
Paso 4. Seleccionar Configuraciones de OCR
Después de elegir reconocer texto en su archivo(s), deberá seleccionar el idioma del documento y decidir si desea reconocer texto en todas las páginas o especificar un rango. Haga sus selecciones en consecuencia.
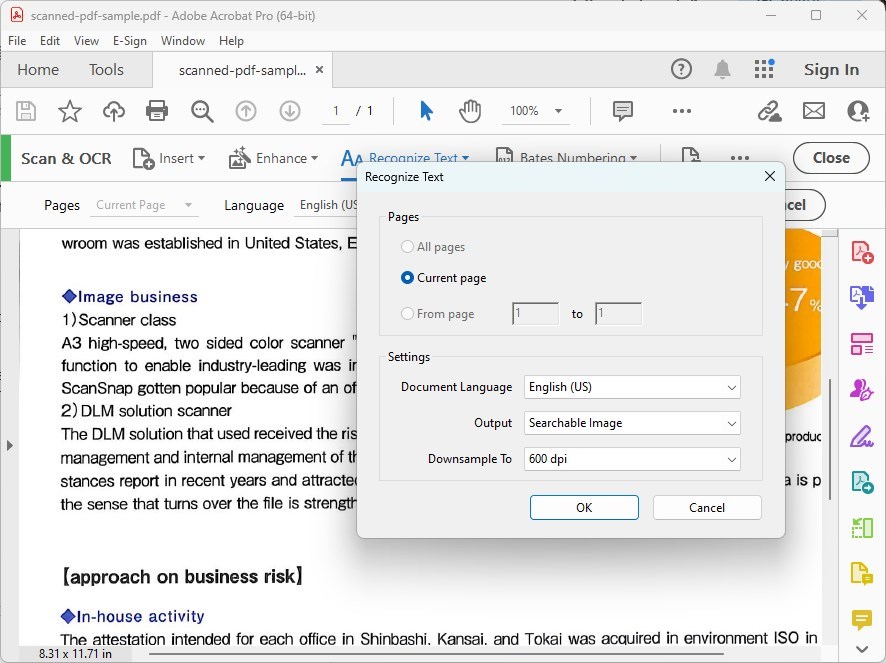
Personalizar las Configuraciones de Reconocimiento de Texto
Haga clic en el botón de “Configuraciones” para acceder a opciones adicionales, como el estilo de salida (Imagen Buscable o Texto e Imágenes Editables) y resolución. Ajuste estas configuraciones según sus necesidades.
Paso 5. Iniciar el Proceso de OCR
Una vez que haya configurado sus ajustes, haga clic en el botón de “Reconocer Texto” para iniciar el proceso de OCR.
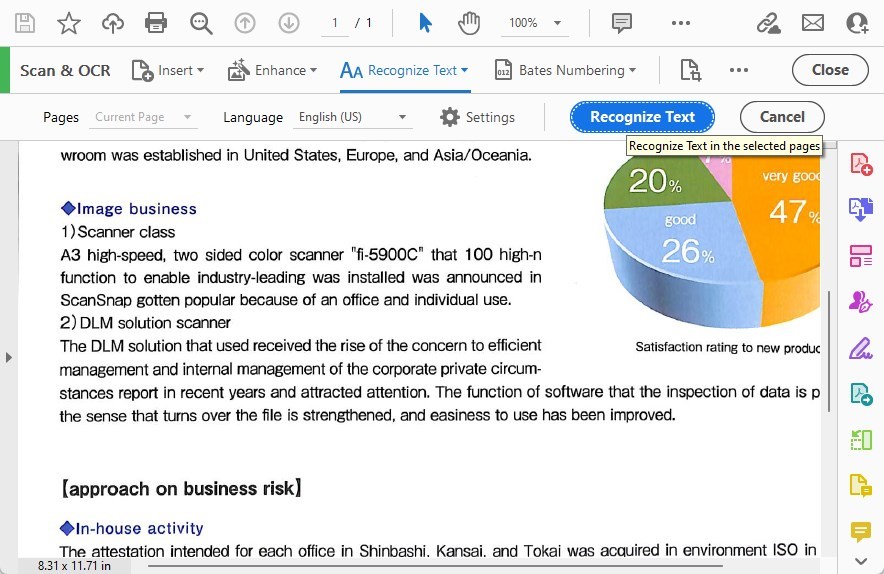
Reconocer Texto en las Páginas Seleccionadas
Adobe Acrobat comenzará a convertir el texto de imagen en su PDF en texto editable y buscable.
Cómo Reconocer Texto en Documentos PDF Escaneados en Google Docs
Google Docs es ampliamente accesible y gratuito para cualquiera con una cuenta de Google. Es basado en la web, por lo que puede acceder a él desde cualquier lugar sin necesidad de instalar software especializado.
Suba y abra el PDF en Google Docs. Google Docs tiene una opción para convertir archivos PDF (e imágenes) en texto editable cuando sube un archivo PDF como un Documento de Google, lo cual puede ser particularmente útil para conversiones rápidas.
Paso 1. Inicie sesión en su cuenta de Google y vaya a Google Drive. Haga clic en el botón “Nuevo” en el lado izquierdo, luego seleccione “Subir archivo“.
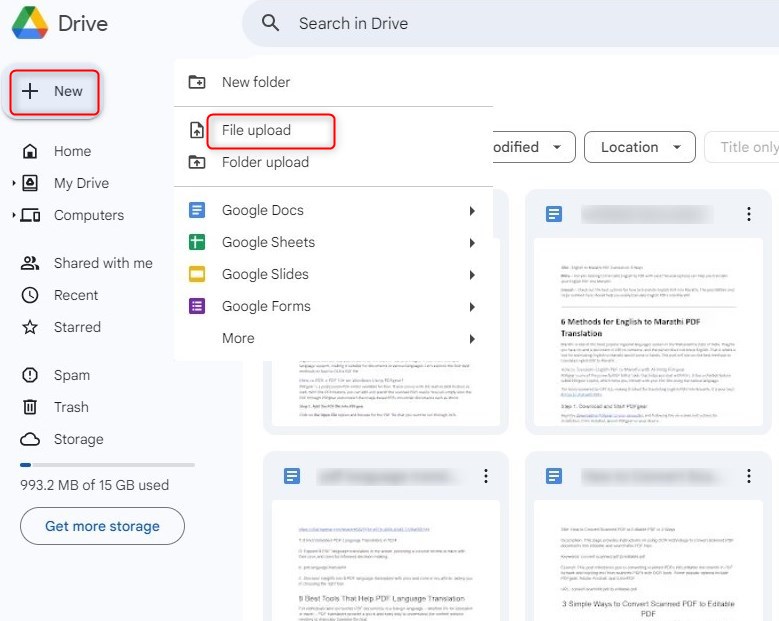
Subir un Archivo a Google Drive
Busque en su computadora el archivo PDF que desea convertir y selecciónelo. El archivo se subirá a su Google Drive.
Paso 2. Una vez que la carga se complete, localice el archivo PDF en su Google Drive.
Haga clic derecho en el archivo, pase el cursor sobre “Abrir con“, y luego seleccione “Google Docs“.
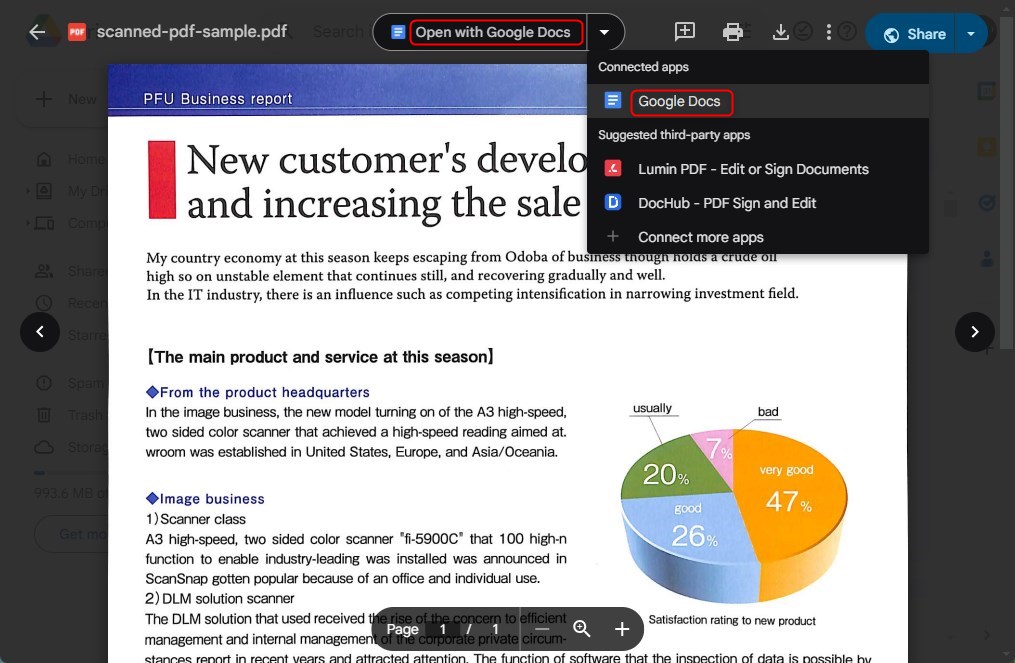
Abrir un PDF Escaneado con Google Docs
Paso 3. Google Docs comenzará automáticamente el proceso de OCR y abrirá el documento como un nuevo archivo de Google Docs.
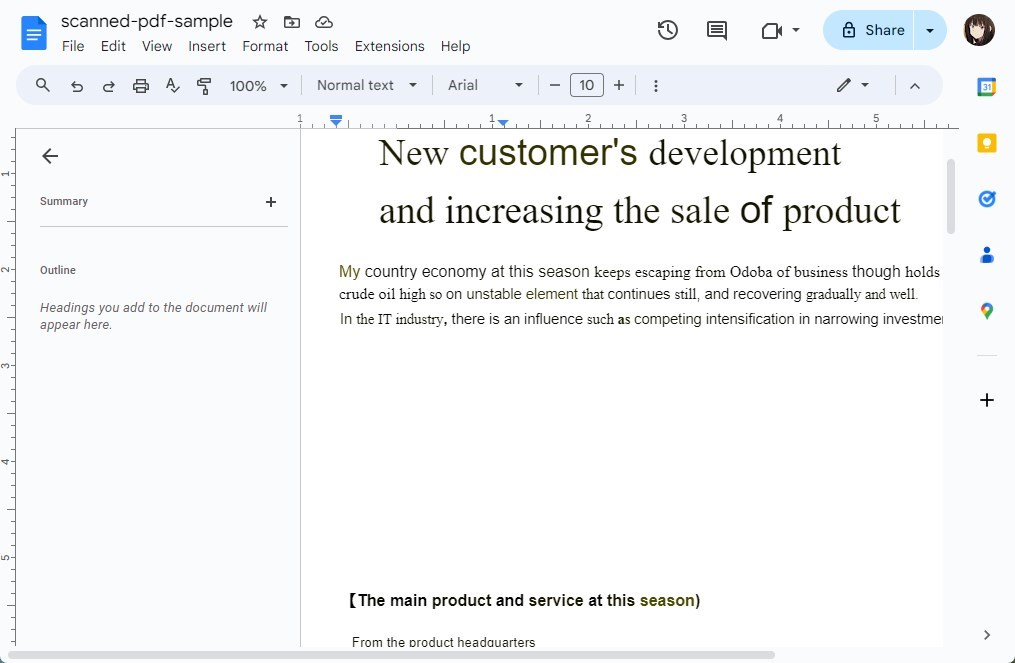
PDF Escaneado Mostrado en Google Docs
Después de que el documento se abra en Google Docs, puede editar el texto según sea necesario. El diseño original del PDF puede no preservarse perfectamente, especialmente si el documento contenía muchas imágenes o formato complejo.
Paso 4. Puede guardar el documento en Google Docs, o descargarlo en varios formatos haciendo clic en “Archivo” > “Descargar”, y luego eligiendo su formato preferido (por ejemplo, Microsoft Word, PDF, Texto Plano, etc.).
Cómo Usar OCR para Reconocer Texto en PDF en Línea Gratis
Sejda ofrece una forma sencilla y eficiente de convertir escaneos de PDF en texto y PDFs buscables, así como extraer texto de escaneos.
Esta herramienta en línea es gratuita para documentos de hasta 10 páginas o 50 MB y permite hasta 3 tareas por hora. Para documentos más grandes, hay un servicio PRO disponible para documentos de hasta 100 páginas.
Paso 1. Vaya a la página de la herramienta OCR PDF de Sejda en su navegador web.
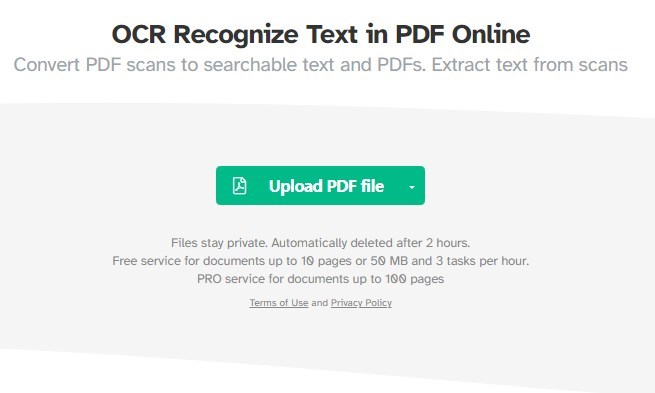
Usar la Herramienta OCR PDF de Sejda
Paso 2. Haga clic en “Subir archivos PDF” para seleccionar un PDF desde su computadora o arrástrelo a la página. También puede usar archivos de Dropbox o Google Drive.
Paso 3. Seleccione el idioma del documento en el menú desplegable para mejorar la precisión.
Elija si desea un PDF buscable o salida de texto plano, o ambos.
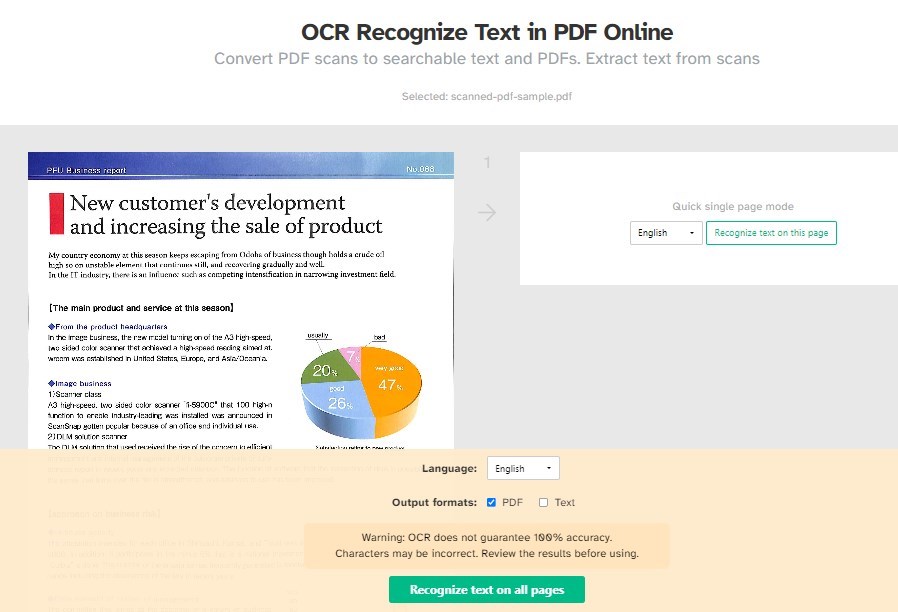
OCR Reconocer Texto en PDF en Línea
Paso 4. Haga clic en el botón verde en la parte inferior de la página para comenzar a reconocer el texto. Puede tardar un poco, dependiendo del tamaño del archivo.
Paso 5. Después de que termine, descargue el archivo resultante haciendo clic en “Descargar”. Puede obtener el PDF buscable o el archivo de texto, o ambos por separado si ha elegido ambas opciones.
Conclusión
Para reconocer texto en PDFs, tiene opciones. Puede usar herramientas gratuitas como PDFgear y Google Docs. También está Sejda, que tiene límites en la cantidad de archivos que puede usar, y Adobe Acrobat, que debe pagar.
Cada opción ayuda a hacer que los PDFs sean editables y buscables, atendiendo a diferentes necesidades, desde opciones gratuitas hasta herramientas profesionales.