4 méthodes simples pour reconnaître le texte dans un PDF

Sommaire :
L’article décrit 4 manières de reconnaître le texte dans les PDFs, en soulignant l’importance de l’OCR (reconnaissance optique de caractères) pour convertir les PDFs basés sur des images en PDFs basés sur du texte pour faciliter l’édition et l’interaction.
Navigation

Comment reconnaître le texte dans un PDF
La reconnaissance de texte dans les PDF, généralement grâce à la technologie OCR, est cruciale pour transformer les documents basés sur des images en formats éditables et consultables. Ce processus rend les documents plus faciles d’accès. Il vous permet également d’extraire et éditer des données plus facilement.
De plus, il aide à mieux stocker les informations numériques et à les retrouver facilement. Cela est très important pour les entreprises, les chercheurs et les éducateurs.
Reconnaître gratuitement le texte d’un PDF scanné avec PDFgear
PDFgear est un outil OCR (reconnaissance optique de caractères) gratuit conçu pour rendre les PDF scannés éditables ou pour extraire du texte à partir de documents qui ne permettent pas la sélection de texte. Il offre une fonctionnalité OCR de zone pour une extraction rapide de texte de zones spécifiques d’un PDF.
Contrairement à de nombreux autres éditeurs de PDF qui placent les fonctionnalités OCR derrière un mur de paiement, PDFgear offre des capacités OCR précises et multilingues sans coût. Voici comment utiliser PDFgear pour reconnaître du texte dans un PDF scanné :
Étape 1. Ajouter le fichier PDF à PDFgear
Tout d’abord, téléchargez et installez PDFgear sur Windows ou Mac. Lancez PDFgear sur votre ordinateur.
Ouvrir un PDF avec PDFgear
Cliquez sur “Ouvrir le fichier“. Choisissez le PDF à partir duquel vous souhaitez extraire le texte et cliquez sur “Ouvrir“.
Étape 2. Sélectionnez la fonctionnalité OCR
Recherchez la fonctionnalité “OCR” dans l’onglet “Page d’accueil”. Cliquez sur “OCR” pour l’activer.
Utilisez votre souris pour surligner le texte que vous souhaitez extraire. Relâchez le bouton de la souris une fois le texte sélectionné.
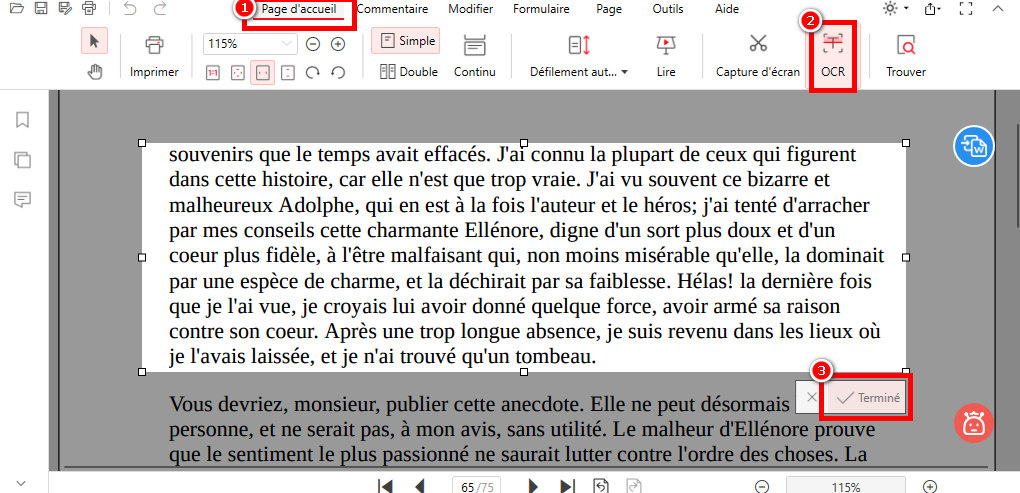
Effectuer l’OCR sur un PDF scanné
Étape 3. Enregistrez ou extrayez la section sélectionnée
Cliquez sur “Terminé” pour traiter. Une boîte de dialogue s’ouvrira pour copier ou enregistrer le texte sélectionné et pour choisir la langue du document original pour de meilleurs résultats.
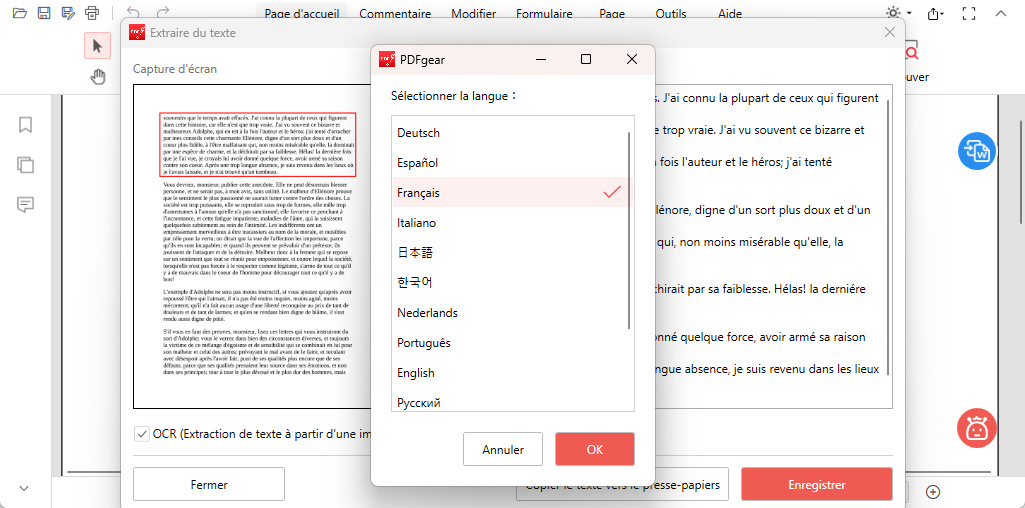
Choisir la langue d’extraction du texte
Vous pouvez soit copier le texte dans le presse-papiers, soit cliquer sur “Enregistrer” pour enregistrer le fichier au format TXT.
Reconnaître le texte d’un PDF scanné avec Adobe Acrobat
Utilisez la fonctionnalité OCR intégrée d’Adobe Acrobat. Cette fonctionnalité permet aux utilisateurs de convertir des PDF uniquement image en documents lisibles en reconnaissant la plupart des textes.
Cet outil puissant peut reconnaître et convertir précisément le texte dans les PDF, offrant des options pour éditer, rechercher et copier le texte.
Étape 1. Ouvrez votre PDF dans Adobe Acrobat Pro DC
Lancez Adobe Acrobat Pro. Ouvrez le document PDF que vous souhaitez reconnaître en cliquant sur “Fichier” > “Ouvrir” et en sélectionnant votre document.
Étape 2. Accédez à l’outil OCR
Une fois votre PDF ouvert, recherchez le panneau “Outils” sur le côté droit de la fenêtre.
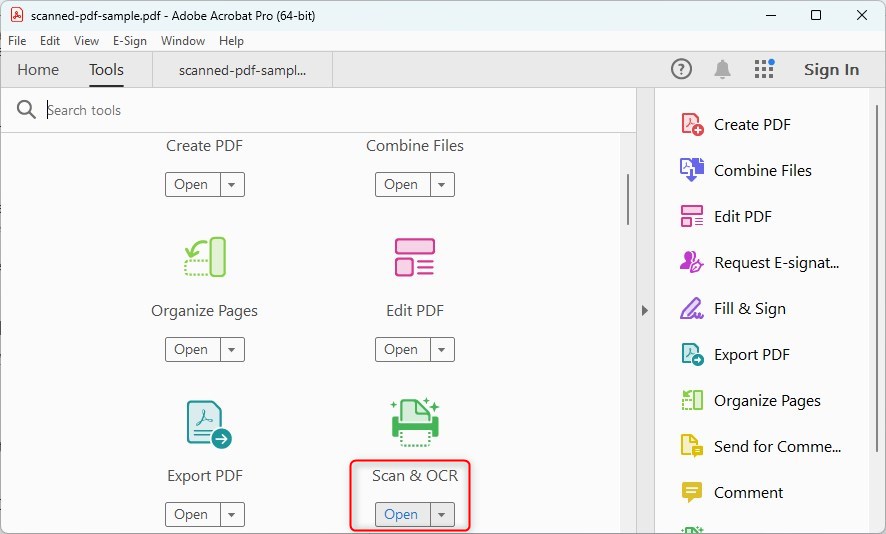
Ouvrir l’outil OCR dans Adobe
Parcourez les outils ou recherchez “Scanner & OCR“. Cliquez dessus pour ouvrir l’ensemble d’outils OCR.
Étape 3. Reconnaître le texte
Dans le panneau “Scanner & OCR“, vous verrez une option qui dit “Reconnaître le texte“. Cliquez dessus.
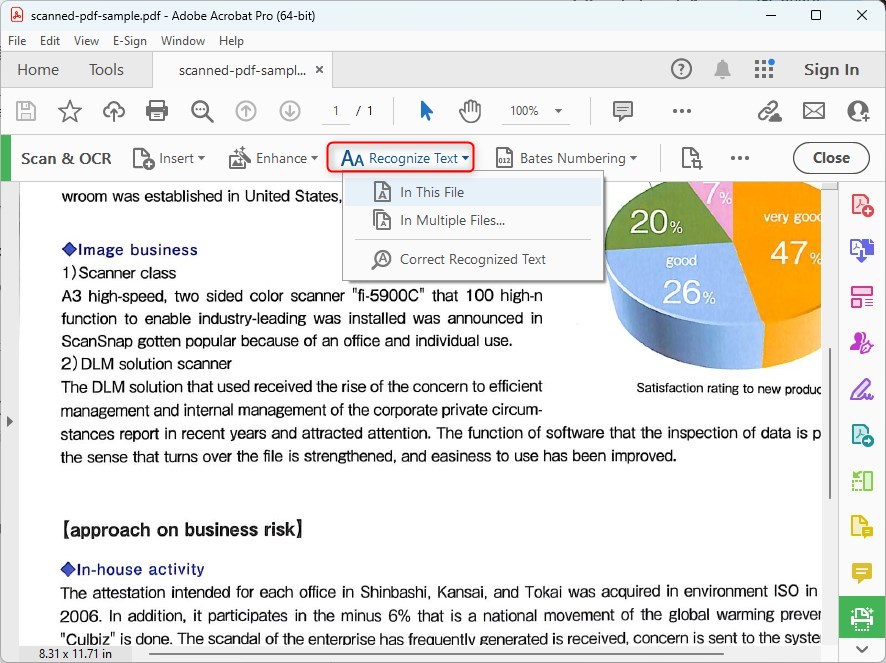
Reconnaître tout le texte dans Adobe Acrobat DC
Vous aurez deux options : “Dans ce fichier” et “Dans plusieurs fichiers“. Choisissez “Dans ce fichier” pour le document que vous avez ouvert, ou “Dans plusieurs fichiers” si vous souhaitez appliquer l’OCR à plusieurs documents à la fois.
Étape 4. Sélectionner les paramètres OCR
Après avoir choisi de reconnaître le texte dans votre fichier, vous devrez sélectionner la langue du document et décider si vous souhaitez reconnaître le texte dans toutes les pages ou spécifier une plage. Faites vos sélections en conséquence.
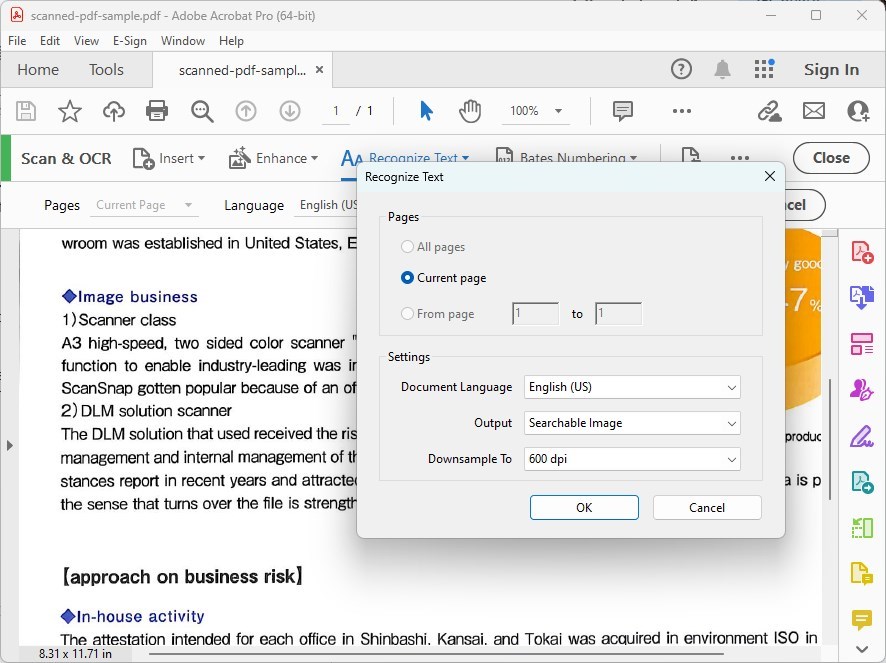
Personnaliser les paramètres de reconnaissance de texte
Cliquez sur le bouton “Paramètres” pour accéder à des options supplémentaires, telles que le style de sortie (Image consultable ou Texte et images éditables) et la résolution. Ajustez ces paramètres selon vos besoins.
Étape 5. Démarrer le processus OCR
Une fois que vous avez configuré vos paramètres, cliquez sur le bouton “Reconnaître le texte” pour démarrer le processus OCR.
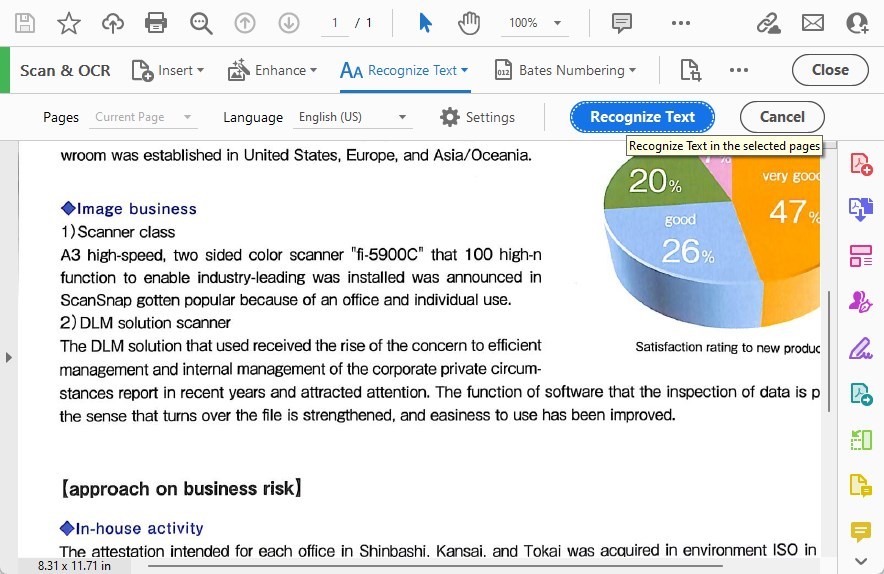
Reconnaître le texte dans les pages sélectionnées
Adobe Acrobat commencera à convertir le texte image dans votre PDF en texte consultable et éditable.
Reconnaître le texte d’un PDF scanné avec Google Docs
Google Docs est largement accessible et gratuit pour quiconque possède un compte Google. Il est basé sur le web, vous pouvez donc y accéder de n’importe où sans avoir besoin d’installer un logiciel spécialisé.
Téléchargez et ouvrez le PDF dans Google Docs. Google Docs a une option pour convertir les fichiers PDF (et les images) en texte éditable lorsque vous téléchargez un fichier PDF en tant que document Google, ce qui peut être particulièrement utile pour des conversions rapides.
Étape 1. Connectez-vous à votre compte Google et allez sur Google Drive. Cliquez sur le bouton “Nouveau” sur le côté gauche, puis sélectionnez “Téléversement de fichiers“.
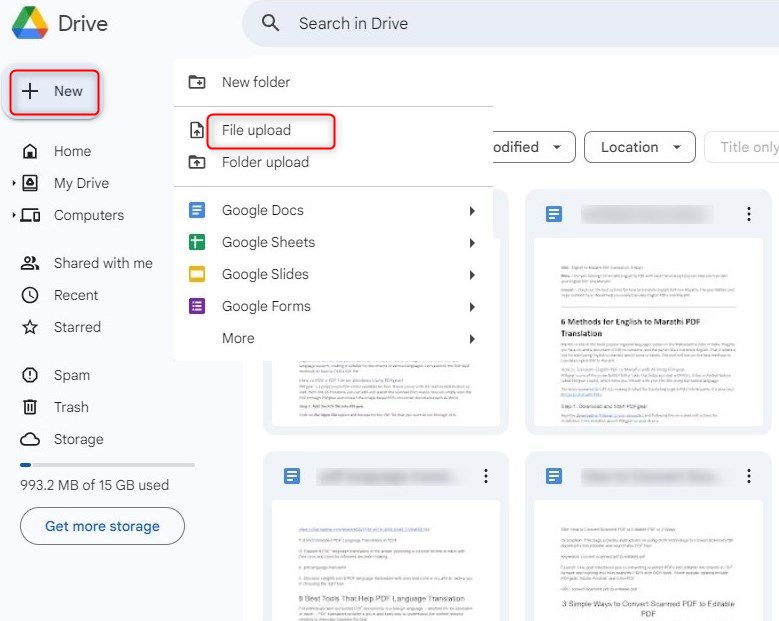
Téléverser un fichier sur Google Drive
Parcourez votre ordinateur pour trouver le fichier PDF que vous souhaitez convertir et sélectionnez-le. Le fichier sera alors téléversé sur votre Google Drive.
Étape 2. Une fois le téléversement terminé, localisez le fichier PDF dans votre Google Drive.
Cliquez avec le bouton droit sur le fichier, survolez “Ouvrir avec“, puis sélectionnez “Google Docs“.
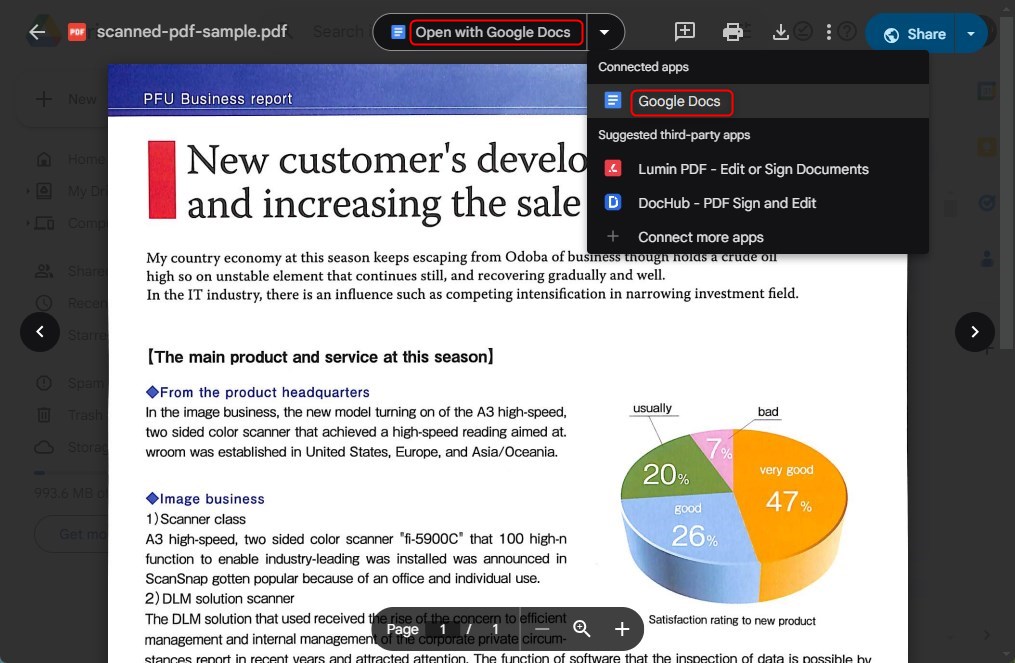
Ouvrir un PDF scanné avec Google Docs
Étape 3. Google Docs commencera automatiquement le processus OCR et ouvrira le document en tant que nouveau fichier Google Docs.
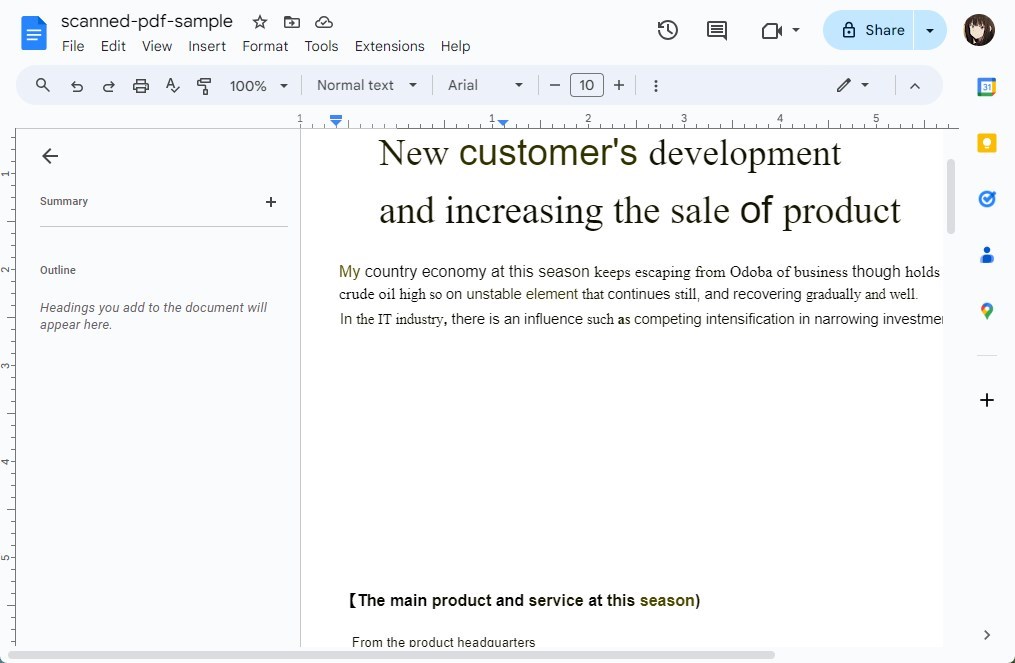
Affichage du PDF scanné dans Google Docs
Après l’ouverture du document dans Google Docs, vous pouvez éditer le texte selon vos besoins. La mise en page originale du PDF peut ne pas être parfaitement préservée, surtout si le document contenait beaucoup d’images ou une mise en page complexe.
Étape 4. Vous pouvez enregistrer le document dans Google Docs, ou le télécharger dans divers formats en cliquant sur “Fichier” > “Télécharger”, puis en choisissant votre format préféré (par exemple, Microsoft Word, PDF, texte brut, etc.).
Utiliser l’OCR gratuite pour les PDF en ligne
Sejda offre un moyen simple et efficace de convertir les scans de PDF en texte et PDF consultables, ainsi que d’extraire du texte des scans.
Cet outil en ligne est gratuit pour les documents jusqu’à 10 pages ou 50 MB et permet jusqu’à 3 tâches par heure. Pour les documents plus volumineux, un service PRO est disponible pour des documents jusqu’à 100 pages.
Étape 1. Allez sur la page de l’outil OCR PDF de Sejda dans votre navigateur web.
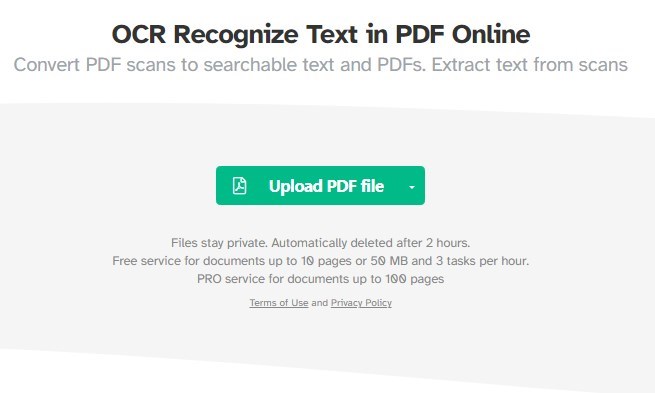
Utiliser l’outil OCR PDF de Sejda
Étape 2. Cliquez sur “Téléverser des fichiers PDF” pour choisir un PDF depuis votre ordinateur ou faites-le glisser sur la page. Vous pouvez également utiliser des fichiers depuis Dropbox ou Google Drive.
Étape 3. Sélectionnez la langue du document dans le menu déroulant pour améliorer la précision.
Choisissez si vous voulez une sortie PDF consultable ou un texte brut, ou les deux.
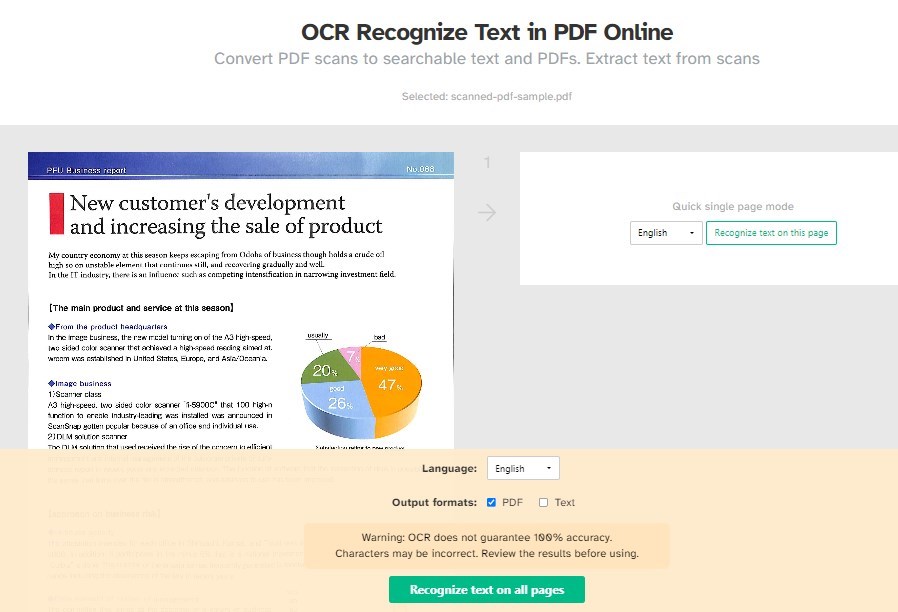
OCR Reconnaître le texte dans un PDF en ligne
Étape 4. Cliquez sur le bouton vert en bas de la page pour commencer la reconnaissance du texte. Cela peut prendre un certain temps, selon la taille du fichier.
Étape 5. Après la fin du processus, téléchargez le(s) fichier(s) résultant(s) en cliquant sur “Télécharger”. Vous pouvez obtenir le PDF consultable ou le fichier texte, ou les deux séparément si vous avez choisi les deux options.
Conclusion
Pour reconnaître du texte dans des PDF, vous avez des choix. Vous pouvez utiliser des outils gratuits comme PDFgear et Google Docs. Il y a aussi Sejda, qui a des limites sur le nombre de fichiers que vous pouvez utiliser, et Adobe Acrobat, qui est payant.
Chaque option aide à rendre les PDF éditables et consultables, répondant à différents besoins, des options gratuites aux outils professionnels.