Como Reconhecer e Extrair Texto em Imagem PDF [4 Métodos Simples]

Resumo :
O artigo descreve 4 maneiras de reconhecer texto em PDFs, enfatizando a importância do OCR (Reconhecimento Óptico de Caracteres) para converter PDFs baseados em imagens em PDFs baseados em texto, facilitando a edição e a interação.
Conteúdo

Como Reconhecer Texto em PDF
Reconhecer texto em imagem PDF, normalmente através da tecnologia OCR, é crucial para transformar documentos baseados em imagem em formatos editáveis e pesquisáveis. Este processo torna os documentos mais fáceis de acessar. Também permite que você extraia, edite e armazene informações ou dados mais facilmente.
Como Reconhecer Texto em Imagem PDF com PDFgear Grátis
PDFgear é uma ferramenta OCR (Reconhecimento Óptico de Caracteres) gratuita projetada para reconhecer texto em PDF e tornar PDFs escaneados editáveis ou extrair texto que não permitem a seleção. Ao contrário de muitos outros editores de PDF que colocam os recursos de OCR atrás de um paywall, o PDFgear oferece capacidades de OCR precisas e multilíngues sem custo. Aqui está como usar o PDFgear para reconhecimento de caracteres em um PDF:
Passo 1. Adicione o Arquivo PDF ao PDFgear
Primeiro, baixe e instale o PDFgear no Windows ou Mac. Inicie o PDFgear no seu computador.
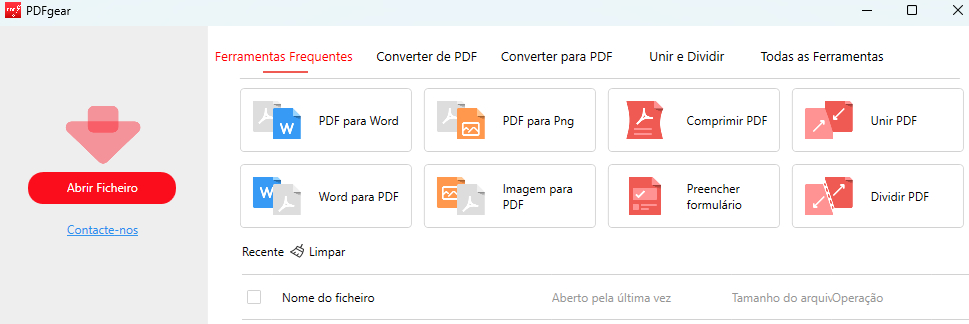
Abra um PDF com o PDFgear
Clique em “Abrir Ficheiro“. Escolha o PDF do qual você quer extrair o texto e clique em “Abrir“.
Passo 2. Selecione o Recurso de OCR
Procure pelo recurso “OCR” na aba “Pagina inicial”. Clique em “OCR” para ativá-lo.
Use o mouse para destacar o texto que você deseja extrair. Solte o botão do mouse uma vez que o texto esteja selecionado.
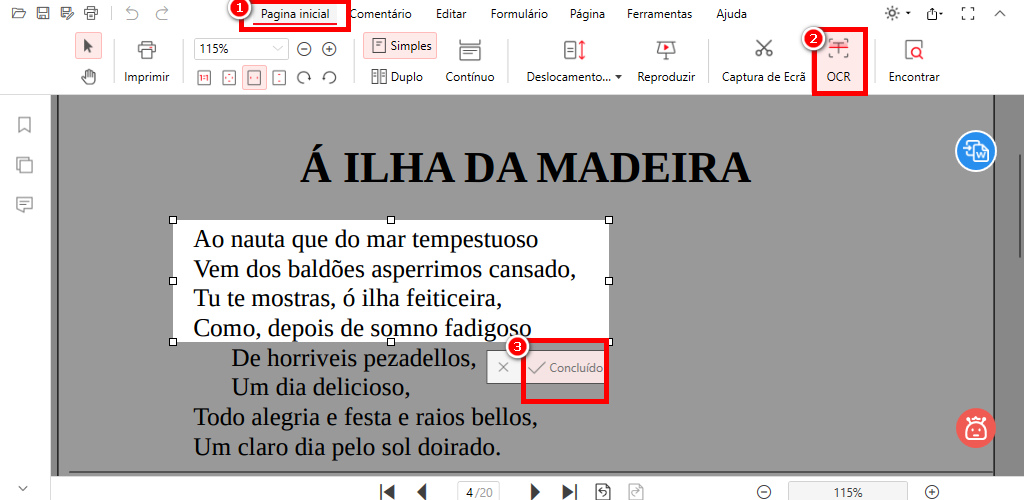
Realizar OCR em um PDF Escaneado
Passo 3. Salve ou Extraia a Seção Selecionada
Clique em “Concluidó” para processar. Uma caixa de diálogo se abrirá para copiar ou salvar o texto selecionado e escolher o idioma do documento original para melhores resultados.
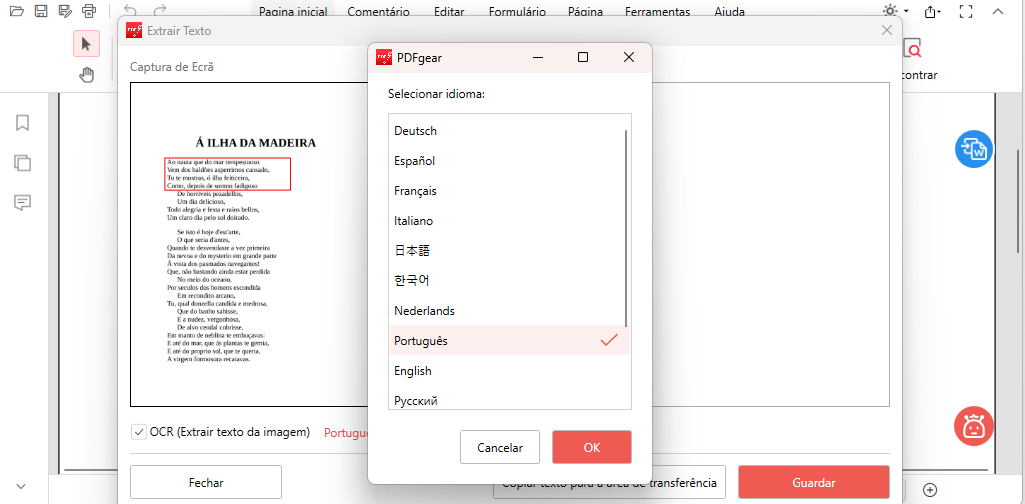
Escolha o Idioma da Extração de Texto
Você pode copiar o texto para a área de transferência ou clicar em “Guardar” para salvar o arquivo em formato TXT.
Como Reconhecer Texto em PDF Online Gratis com OCR
Sejda oferece uma maneira simples e eficiente de converter PDFs escaneados em texto pesquisável e PDFs, bem como extrair texto de escaneamentos.
Esta ferramenta online é gratuita para documentos de até 10 páginas ou 50 MB e permite até 3 tarefas por hora. Para documentos maiores, um serviço PRO está disponível para documentos de até 100 páginas.
Passo 1. Vá para a página da ferramenta Sejda OCR PDF no seu navegador.
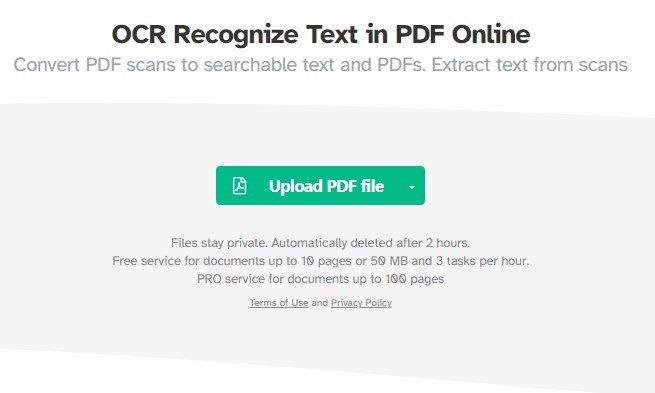
Use a Ferramenta Sejda OCR PDF
Passo 2. Clique em “Carregar arquivos PDF” para escolher um PDF do seu computador ou arraste-o para a página. Você também pode usar arquivos do Dropbox ou Google Drive.
Passo 3. Selecione o idioma do documento no menu suspenso para melhorar a precisão.
Escolha se deseja um PDF pesquisável ou saída de texto simples, ou ambos.
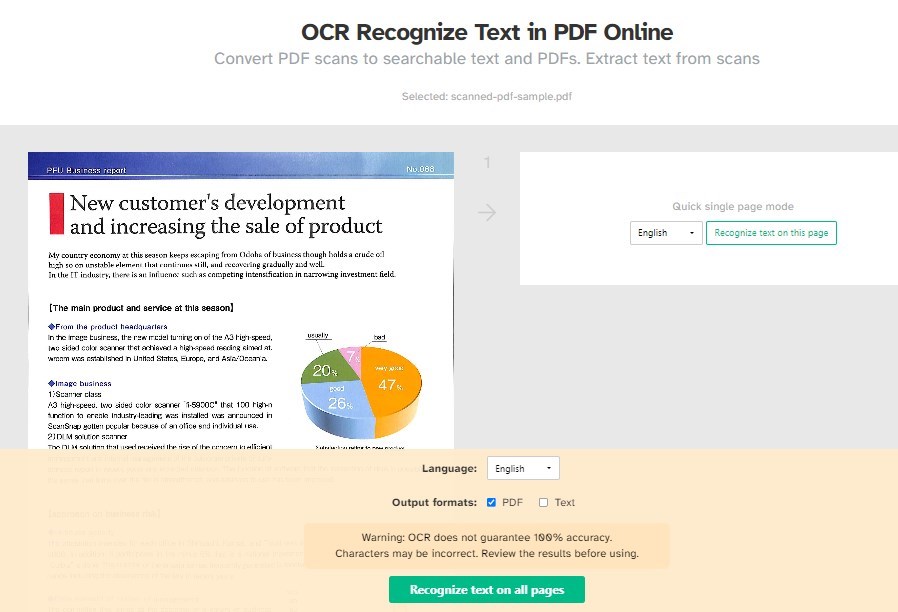
OCR Reconhecer Texto em PDF Online
Passo 4. Clique no botão verde na parte inferior da página para iniciar o reconhecimento de texto. Pode levar um tempo, dependendo do tamanho do arquivo.
Passo 5. Depois de concluído, baixe o(s) arquivo(s) resultante(s) clicando em “Download”. Você pode obter o PDF pesquisável ou o arquivo de texto, ou ambos separadamente se tiver escolhido ambas as opções.
Como Reconhecer Texto em PDF Escaneado com Adobe Acrobat
Com o recurso OCR embutido do Adobe Acrobat, os usuários podem reconhecer caracteres em imagem PDF e converter com precisão dentro de PDFs, oferecendo opções para editar, pesquisar e copiar texto. No entanto, o uso do recurso OCR do Adobe Acrobat requer uma assinatura paga e a versão gratuita não oferece suporte ao reconhecimento de texto.
Passo 1. Abra Seu PDF no Adobe Acrobat Pro DC
Inicie o Adobe Acrobat Pro. Abra o documento PDF que você deseja reconhecer texto clicando em “Arquivo” > “Abrir” e selecionando seu documento.
Passo 2. Acesse a Ferramenta de OCR
Uma vez que seu PDF esteja aberto, procure pelo painel “Ferramentas” no lado direito da janela.
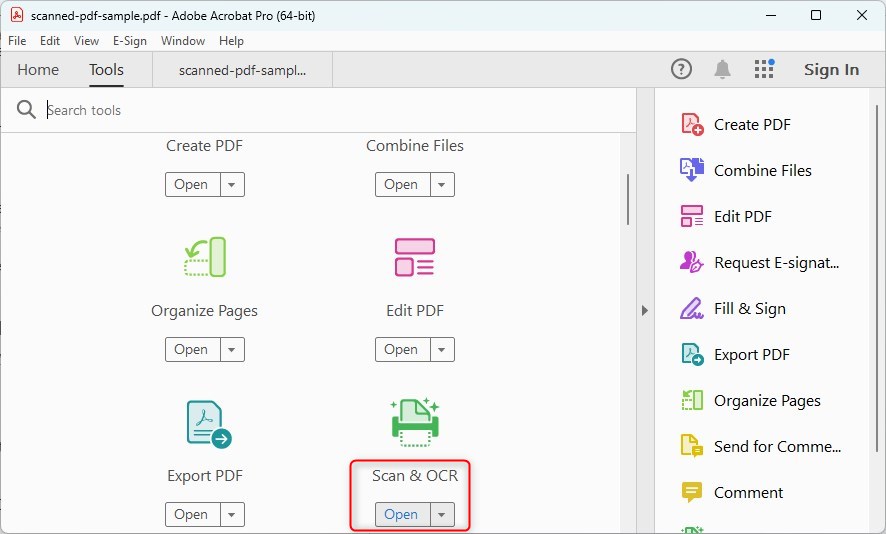
Abra a Ferramenta de OCR no Adobe
Role pelas ferramentas ou pesquise por “Digitalização e OCR”. Clique para abrir o conjunto de ferramentas de OCR.
Passo 3. Reconheça o Texto
No painel “Digitalização e OCR”, você verá uma opção que diz “Reconhecer texto”. Clique nela.
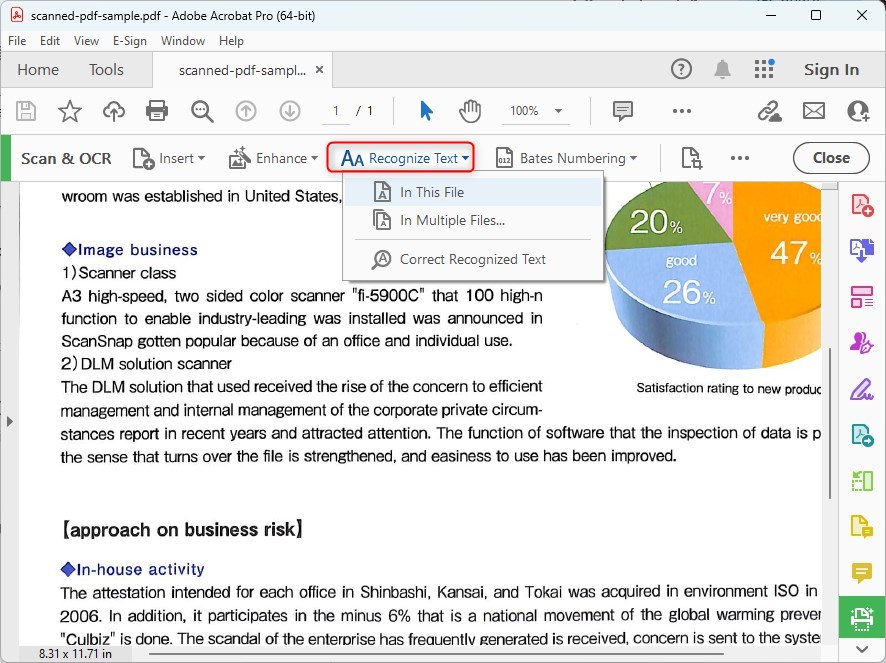
Reconhecer Todo o Texto no Adobe Acrobat DC
Você será apresentado a duas opções: “Neste arquivo” e “Em vários arquivos”. Escolha “Neste arquivo” para o documento que você abriu, ou “Em vários arquivos” se desejar aplicar OCR a vários documentos de uma vez.
Passo 4. Selecione as Configurações de OCR
Após escolher reconhecer texto em seu(s) arquivo(s), você precisará selecionar o idioma do documento e decidir se deseja reconhecer texto em todas as páginas ou especificar um intervalo. Faça suas seleções de acordo.
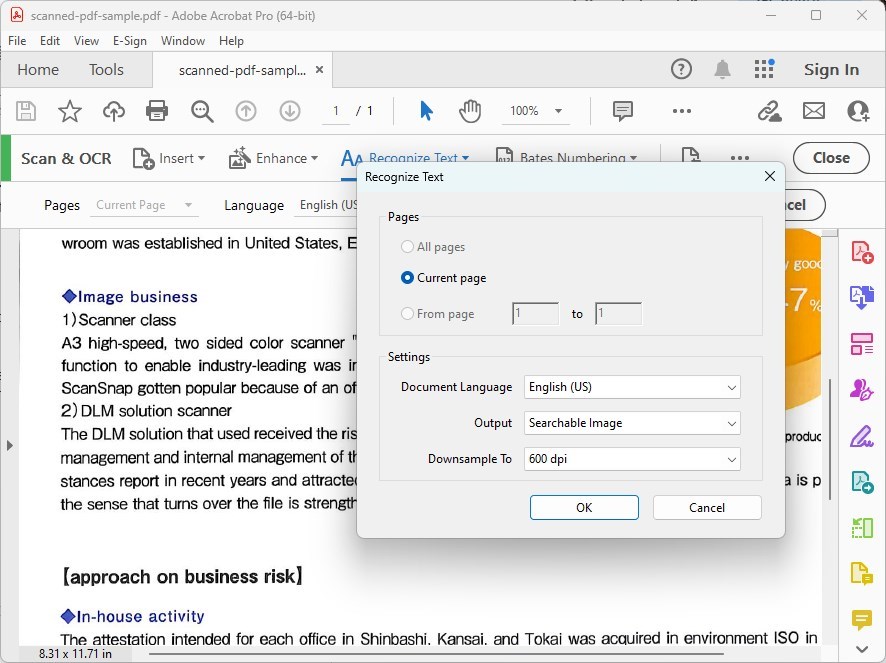
Personalize as Configurações de Reconhecimento de Texto
Clique no botão “Settings” para acessar opções adicionais, como o estilo de saída (Imagem Pesquisável ou Texto e Imagens Editáveis) e resolução. Ajuste essas configurações conforme suas necessidades.
Passo 5. Inicie o Processo de OCR
Uma vez que você tenha configurado suas configurações, clique no botão “Recognize Text” para iniciar o processo de OCR.
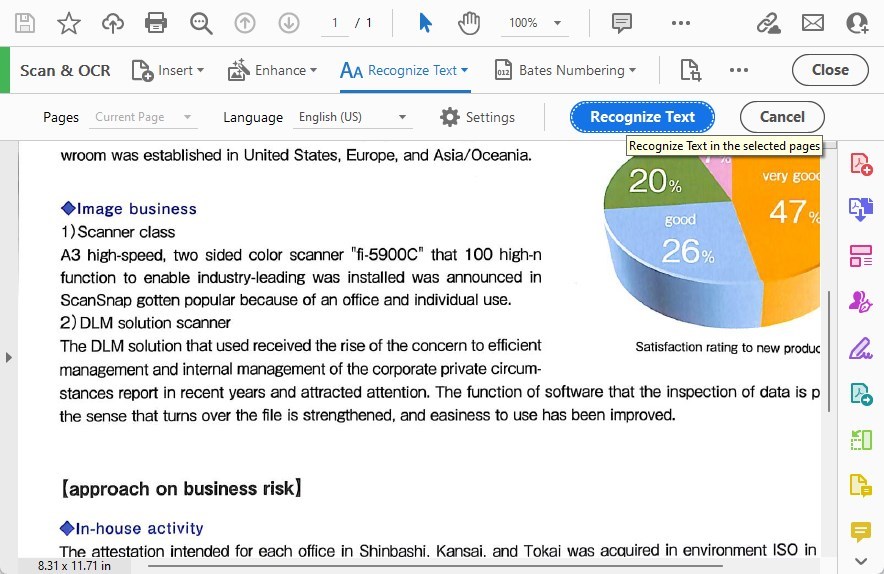
Reconhecer Texto nas Páginas Selecionadas
O Adobe Acrobat começará a converter o texto de imagem no seu PDF em texto pesquisável e editável.
Como Reconhecer Texto em PDF Escaneado no Google Docs
O Google Docs é amplamente acessível e gratuito para qualquer pessoa com uma conta Google. É baseado na web, então você pode acessá-lo de qualquer lugar sem precisar instalar software especializado.
Faça o upload e abra o PDF no Google Docs. O Google Docs tem uma opção para converter arquivos PDF (e imagens) em texto editável quando você faz o upload de um arquivo PDF como um Documento Google, o que pode ser particularmente útil para conversões rápidas.
Passo 1. Faça login na sua conta Google e vá para Google Drive. Clique no botão “Nova” no lado esquerdo e selecione “Carregamento de arquivo”.
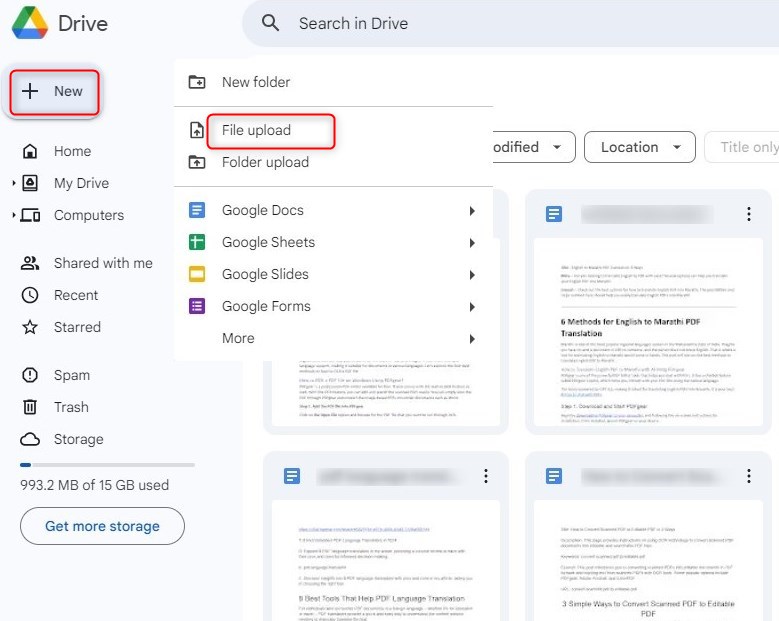
Faça Upload de um Arquivo para o Google Drive
Procure no seu computador o arquivo PDF que você deseja converter e selecione-o. O arquivo será então enviado para o seu Google Drive.
Passo 2. Uma vez que o upload esteja completo, localize o arquivo PDF no seu Google Drive.
Clique com o botão direito no arquivo, passe o cursor sobre “Abrir com” e selecione “Google Docs“.
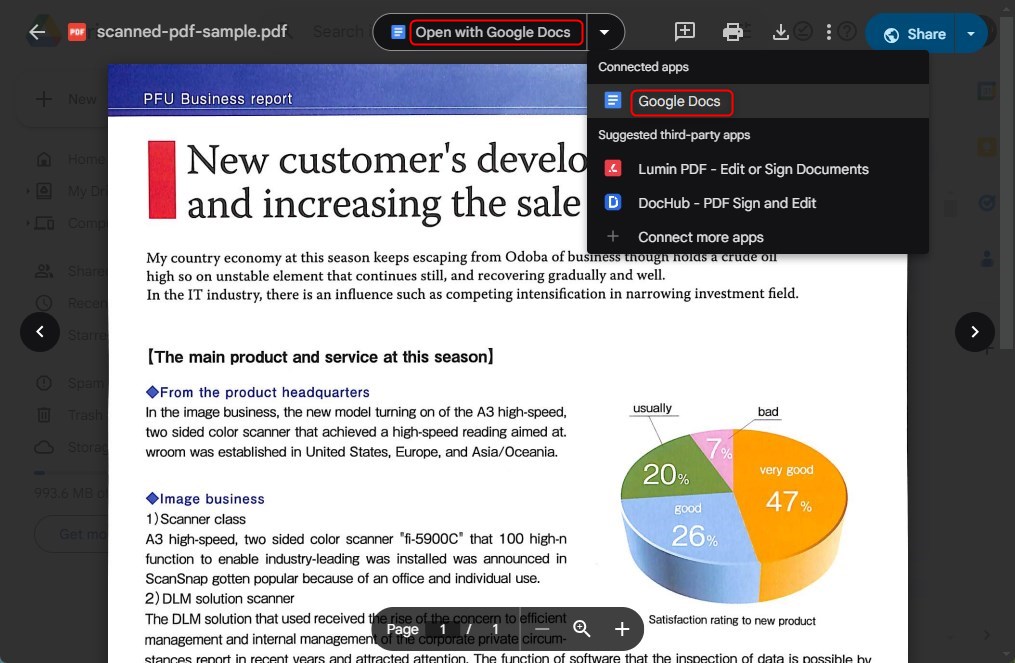
Abra um PDF Escaneado com o Google Docs
Passo 3. O Google Docs começará automaticamente o processo de OCR e abrirá o documento como um novo arquivo do Google Docs.
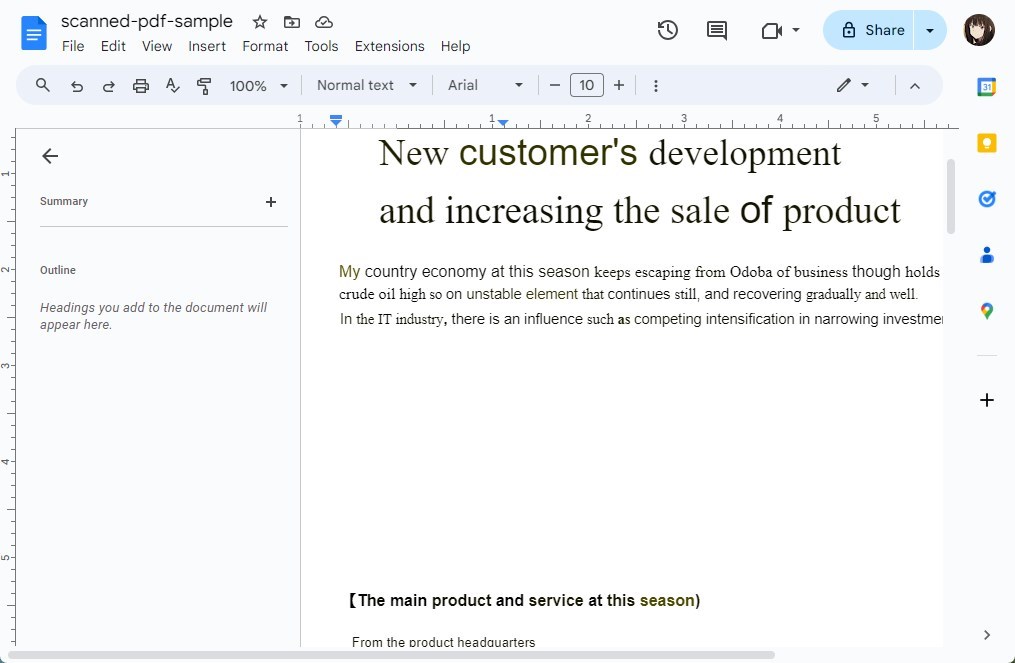
Exibição de PDF Escaneado no Google Docs
Depois que o documento abrir no Google Docs, você pode editar o texto conforme necessário. O layout original do PDF pode não ser perfeitamente preservado, especialmente se o documento contiver muitas imagens ou formatação complexa.
Passo 4. Você pode salvar o documento no Google Docs, ou baixá-lo em vários formatos clicando em “Arquivo” > “Download” e escolhendo o formato desejado (por exemplo, Microsoft Word, PDF, Texto Simples, etc.).
Conclusão
Para reconhecer texto em PDFs, você tem opções. Pode usar ferramentas gratuitas como PDFgear e Google Docs. Há também o Sejda, que tem limites na quantidade de arquivos que você pode usar, e o Adobe Acrobat, que é pago.
Cada opção ajuda a tornar PDFs editáveis e pesquisáveis, atendendo a diferentes necessidades, desde opções gratuitas até ferramentas profissionais.