3 kostenlose Tools für PDF-Texterkennung, die Sie kennen sollten

Überblick:
Möchten Sie den Text in PDF erkennen, um ihn zu übersetzen oder weiterzuverarbeiten? Egal, ob Sie eine Teil- oder Volltexterkennung benötigen, dieser Artikel bietet Ihnen drei praktische Lösungen: pdfgear, Google Docs und Online-OCR-Tools.
Inhaltsverzeichnis

Wie man Text in PDF
Sie möchten Informationen aus einem PDF-Dokument extrahieren, um sie an anderer Stelle aufzuzeichnen oder zu übersetzen? Oder vielleicht möchten Sie eine Volltextsuche durchführen?
In diesem Artikel stellen wir Ihnen drei verschiedene Ansätze vor: die Nutzung von PDFgear für eine teilweise oder vollständige Texterkennung, das Öffnen des PDF-Dokuments in Google Docs oder die Verwendung von Online-OCR-Tools zur Identifizierung des gesamten Textinhalts.
Ein kostenloses Tool zur Erkennung von PDF-Texten (ganz oder teilweise)
PDFgear ist ein kostenloses OCR-Tool (Optical Character Recognition), das entwickelt wurde, um gescannte PDFs bearbeitbar zu machen oder um Text aus Dokumenten zu extrahieren, die keine Texterfassung zulassen. Es bietet eine Bereichs-OCR-Funktion für schnelle Textextraktion aus bestimmten Bereichen eines PDFs.
Im Gegensatz zu vielen anderen PDF-Editoren, die OCR-Funktionen hinter einer Bezahlschranke platzieren, bietet PDFgear genaue und mehrsprachige OCR-Funktionen kostenlos an. So verwenden Sie PDFgear, um Text in einem gescannten PDF zu erkennen:
Schritt 1. Fügen Sie die PDF-Datei zu PDFgear hinzu
Laden Sie zunächst PDFgear für Windows oder Mac herunter und installieren Sie es. Starten Sie PDFgear auf Ihrem Computer.
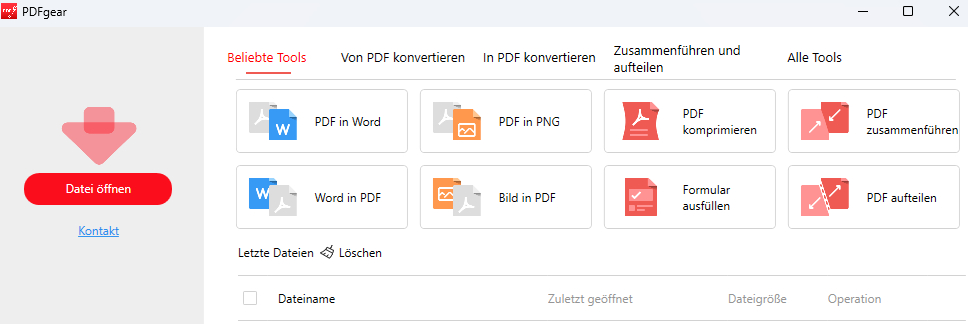
Öffnen Sie ein PDF mit PDFgear
Klicken Sie auf “Datei öffnen“. Wählen Sie das PDF aus, aus dem Sie Text extrahieren möchten, und klicken Sie auf “Öffnen“.
Schritt 2. Wählen Sie die OCR-Funktion
Suchen Sie nach der “OCR“-Funktion in der Registerkarte “Startseite”. Klicken Sie auf “OCR”, um es zu aktivieren.
Verwenden Sie Ihre Maus, um den Text hervorzuheben, den Sie extrahieren möchten. Lassen Sie die Maustaste los, sobald der Text ausgewählt ist.
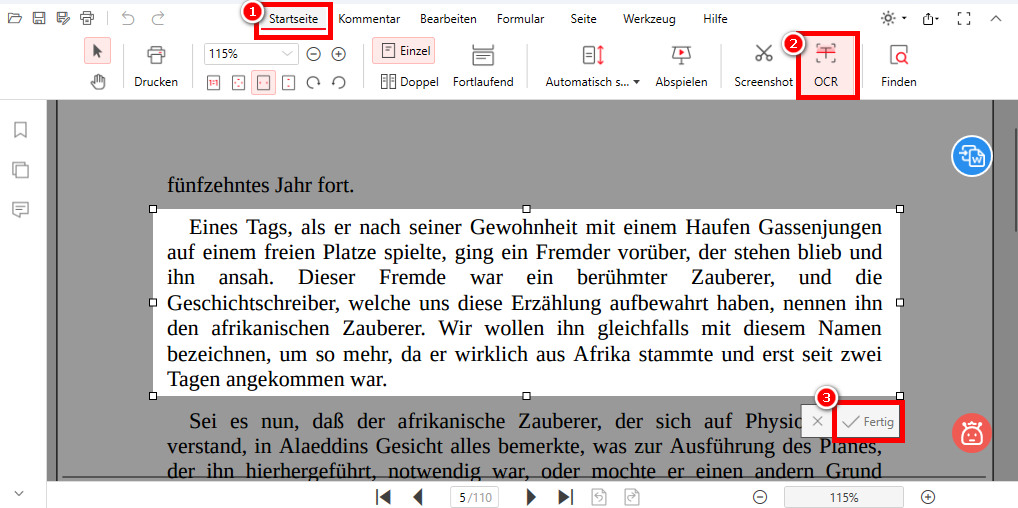
Führen Sie OCR auf ein gescanntes PDF durch
Schritt 3. Speichern oder extrahieren Sie den ausgewählten Abschnitt
Klicken Sie auf “Fertig“, um zu verarbeiten. Ein Dialogfeld wird geöffnet, um den ausgewählten Text zu kopieren oder zu speichern und die Sprache des Originaldokuments für bessere Ergebnisse auszuwählen.
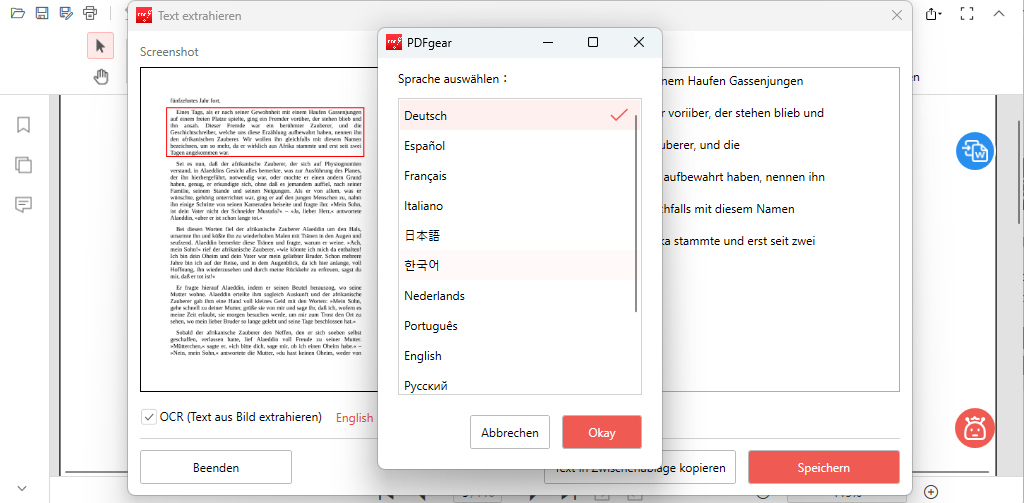
Wählen Sie die Textextraktionssprache
Sie können den Text entweder in die Zwischenablage kopieren oder auf “Speichern” klicken, um die Datei im TXT-Format zu speichern.
So erkennen Sie Text in gescannten PDFs mit Google Docs
Google Docs ist weit zugänglich und kostenlos für alle, die ein Google-Konto haben. Es ist webbasiert, sodass Sie von überall darauf zugreifen können, ohne spezielle Software installieren zu müssen.
Laden Sie das PDF in Google Docs hoch und öffnen Sie es. Google Docs hat eine Option, PDF-Dateien (und Bilder) in bearbeitbaren Text zu konvertieren, wenn Sie eine PDF-Datei als Google-Dokument hochladen. Dies kann besonders nützlich für schnelle Konvertierungen sein.
Schritt 1. Melden Sie sich bei Ihrem Google-Konto an und gehen Sie zu Google Drive. Klicken Sie auf die “Neu“-Schaltfläche auf der linken Seite und wählen Sie “Datei-Hochladen“.
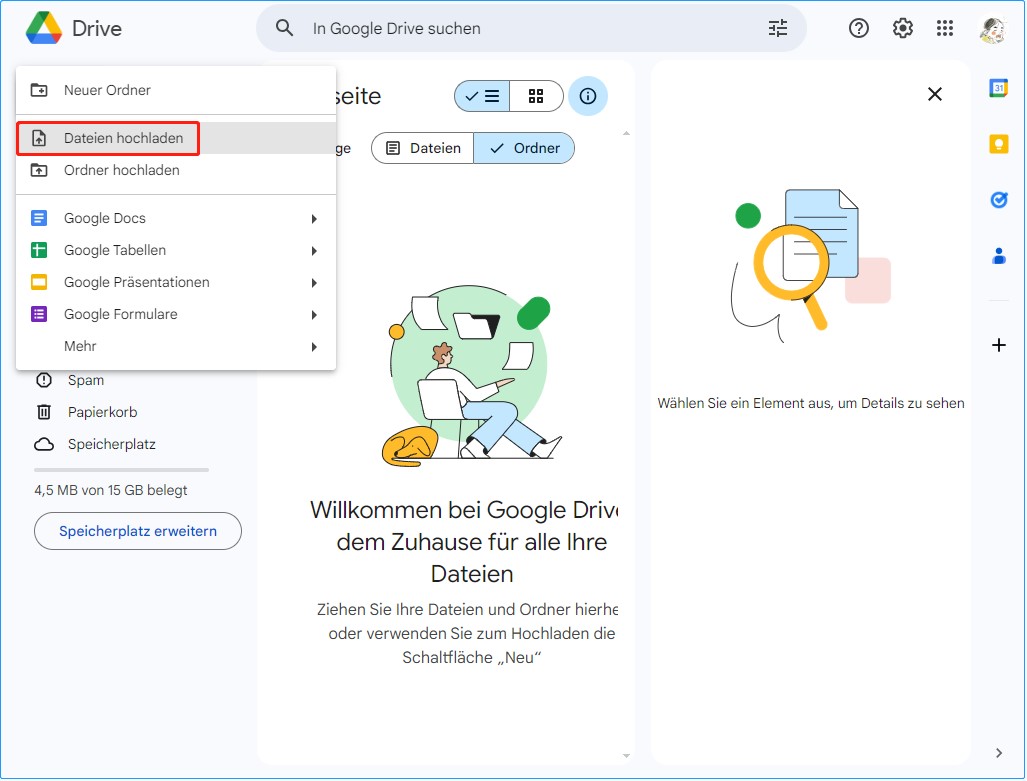
PDF-Datei auf Google Drive hochladen
Durchsuchen Sie Ihren Computer nach der PDF-Datei, die Sie konvertieren möchten, und wählen Sie sie aus. Die Datei wird dann in Ihr Google Drive hochgeladen.
Schritt 2. Sobald der Upload abgeschlossen ist, suchen Sie die PDF-Datei in Ihrem Google Drive.
Klicken Sie mit der rechten Maustaste auf die Datei, fahren Sie mit der Maus über “Öffnen mit” und wählen Sie dann “Google Docs“.
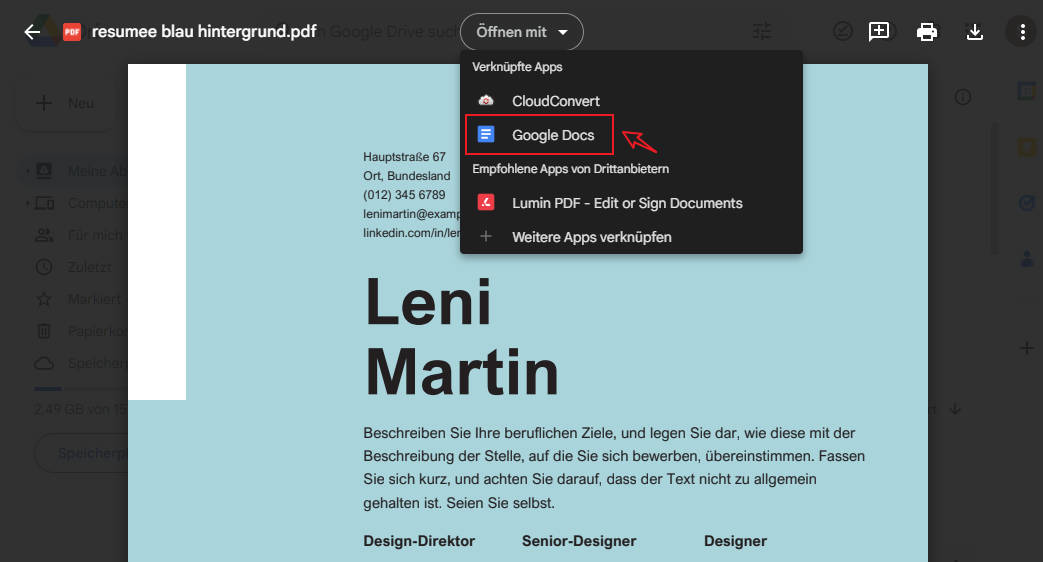
Schritt 3. Google Docs wird automatisch den OCR-Prozess starten und das Dokument als neues Google Docs-Dokument öffnen.
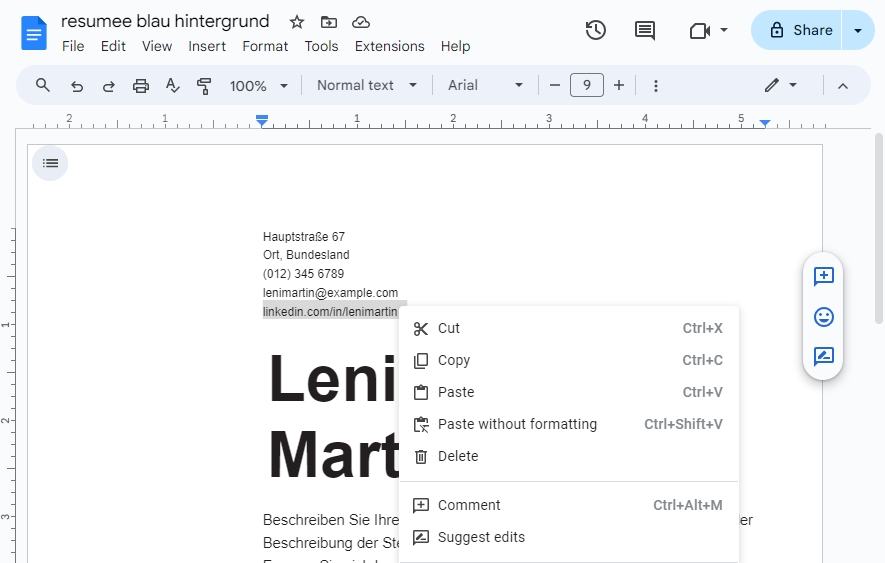
PDF Text erkeent von Google Docs
Nachdem das Dokument in Google Docs geöffnet wurde, können Sie den Text nach Bedarf bearbeiten. Das ursprüngliche Layout des PDFs wird möglicherweise nicht perfekt beibehalten, insbesondere wenn das Dokument viele Bilder oder komplexe Formatierungen enthält.
Schritt 4. Sie können das Dokument in Google Docs speichern oder es in verschiedenen Formaten herunterladen, indem Sie auf “Datei” > “Herunterladen” klicken und dann Ihr bevorzugtes Format auswählen (z. B. Microsoft Word, PDF, Nur-Text usw.).
Wie man OCR-Text in PDF online kostenlos erkennt
Sejda bietet eine einfache und effiziente Möglichkeit, PDF-Scans in durchsuchbaren Text und PDFs zu konvertieren sowie Text aus Scans zu extrahieren.
Dieses Online-Tool ist kostenlos für Dokumente bis zu 10 Seiten oder 50 MB und erlaubt bis zu 3 Aufgaben pro Stunde. Für größere Dokumente ist ein PRO-Service verfügbar, der Dokumente bis zu 100 Seiten unterstützt.
Schritt 1. Gehen Sie zur Sejda OCR PDF Tool in Ihrem Webbrowser.
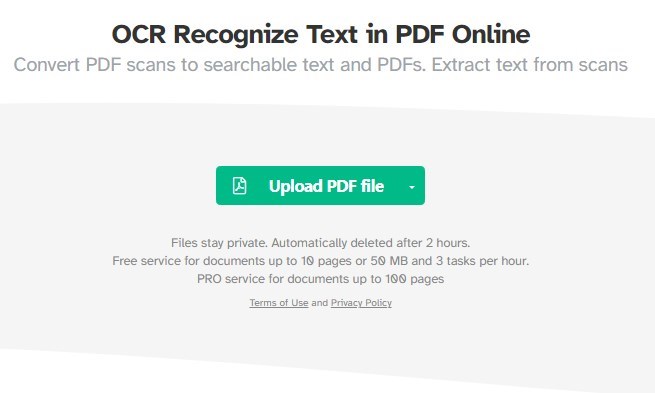
Verwenden Sie das Sejda OCR PDF Tool
Schritt 2. Klicken Sie auf “PDF-Dateien hochladen“, um ein PDF von Ihrem Computer auszuwählen, oder ziehen Sie es auf die Seite. Sie können auch Dateien von Dropbox oder Google Drive verwenden.
Schritt 3. Wählen Sie die Sprache des Dokuments aus dem Dropdown-Menü aus, um die Genauigkeit zu verbessern.
Wählen Sie, ob Sie ein durchsuchbares PDF oder Nur-Text-Ausgabe, oder beides möchten.
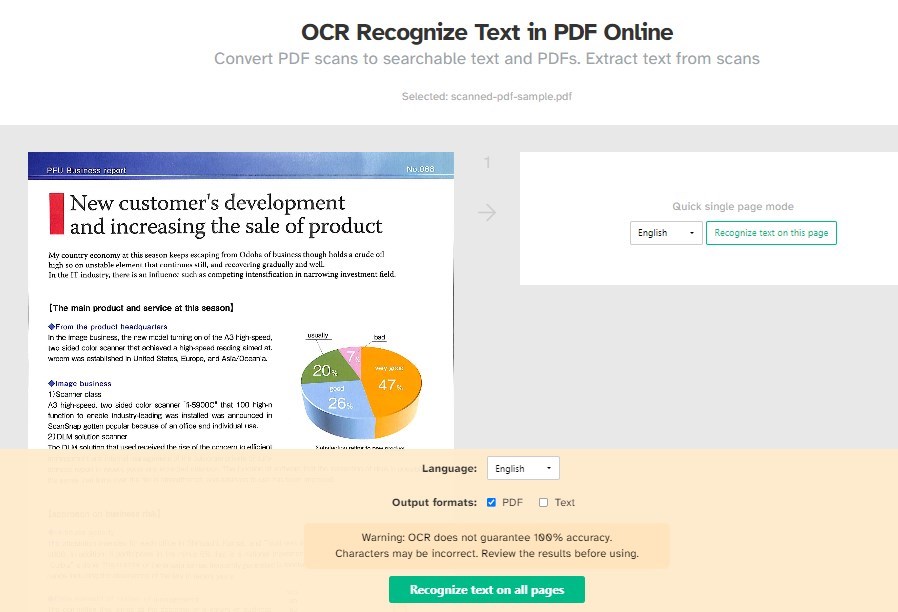
OCR-Text in PDF online erkennen
Schritt 4. Klicken Sie auf die grüne Schaltfläche unten auf der Seite, um die Texterkennung zu starten. Es könnte eine Weile dauern, je nach Dateigröße.
Schritt 5. Nachdem es fertig ist, laden Sie die resultierende Datei(en) herunter, indem Sie auf “Herunterladen” klicken. Sie können das durchsuchbare PDF oder die Textdatei, oder beides separat erhalten, wenn Sie beide Optionen gewählt haben.
Häufig gestellte Fragen zur PDF-Texterkennung
I. Wie funktioniert die Texterkennung in PDFs?
Die Texterkennung in PDFs, auch Optical Character Recognition (OCR) genannt, ist ein Prozess, bei dem ein Computerprogramm die in einem Bild dargestellten Zeichen (Buchstaben, Zahlen, Symbole) erkennt und in editierbaren Text umwandelt. Dabei werden die Bildinformationen analysiert und mit gespeicherten Schriftarten verglichen. Die erkannten Zeichen werden dann in einem Textformat wie beispielsweise TXT oder DOCX gespeichert.
II. Wie kann ich die Qualität der Texterkennung verbessern?
Die Qualität der Texterkennung hängt von verschiedenen Faktoren ab:
- Hohe Auflösung beim Scannen ist entscheidend, ebenso wie ein ausreichender Kontrast zwischen Text und Hintergrund. (Mehr lesen → So erhöhen Sie den PDF-Kontrast und Lesbarkeit online & offline) .
- Schräglagen oder Verzerrungen erschweren die Erkennung.
- Für komplexere Dokumente kann es hilfreich sein, die Sprache und Schriftart in der Software anzugeben.
IIII. Kann ich handschriftlichen Text in einem PDF erkennen lassen?
Die Erkennung von handschriftlichem Text ist deutlich komplexer als die von maschinenschriftlichem Text. Spezielle Handschrifterkennungssoftware ist dafür erforderlich. Die Erkennungsrate hängt stark von der Handschrift, der Qualität des Scans und den Einstellungen der Software ab.
IV. Ist es sicher, sensible Dokumente für die Texterkennung hochzuladen?
Das Hochladen sensibler Dokumente in Online-OCR-Tools birgt Datenschutzrisiken. Die Daten können abgefangen oder missbraucht werden. Offline arbeitende software bietet in der Regel sicherere Lösungen, da die Daten nicht über das Internet übertragen werden.
Wenn Sie sensible Dokumente verarbeiten müssen, sollten Sie lokale/offline OCR-Software wie PDFgear bevorzugen oder sich für Cloud-Lösungen mit starken Datenschutzbestimmungen entscheiden.
Zum Schluss
Um Text in PDFs zu erkennen, haben Sie verschiedene Möglichkeiten. Sie können kostenlose Tools wie PDFgear und Google Docs verwenden. Es gibt auch Sejda, das Grenzen für die Anzahl der Dateien hat, die Sie verwenden können, und Adobe Acrobat, für das Sie bezahlen müssen.
Jede Option hilft dabei, PDFs bearbeitbar und durchsuchbar zu machen und bietet unterschiedliche Lösungen, von kostenlosen bis hin zu professionellen Werkzeugen.