Comment extraire des informations d’un PDF [Texte, Données, Page, Image]

Sommaire :
Vous pourriez être intéressé par l’extraction de données, de pages et d’images d’un document PDF pour réutilisation. Dans cet article, nous apprendrons comment extraire des informations d’un PDF avec un guide complet.
Navigation

Extraire des informations d’un PDF
De nombreux rapports, articles de recherche et jeux de données sont distribués sous forme de PDFs. Passer manuellement au crible des centaines de pages pour trouver des informations pertinentes est extrêmement fastidieux et chronophage.
Vous voulez savoir comment extraire des informations d’un PDF ? Le billet offre un guide détaillé sur comment réaliser chaque type d’extraction. C’est utile pour quiconque souhaite obtenir des informations à partir de PDFs pour l’école, le travail ou un usage personnel.
Extraire du texte à partir d’une image PDF
PDFgear est un éditeur de PDF AI gratuit, offrant de nombreux outils d’édition de PDF avancés qui permettent aux utilisateurs de remplacer, retirer, et ajouter du texte dans un PDF.
Avec sa fonctionnalité OCR intégrée, PDFgear peut vous aider à extraire du texte à partir de PDFs basés sur des images, même si vous ne pouvez pas le sélectionner. Il fonctionne dans plus de 10 langues telles que l’anglais, le français et l’italien. Vous pouvez également sélectionner n’importe quelle partie d’une page PDF pour extraire du texte en utilisant l’OCR.
Étape 1. Ouvrir un document numérisé
Ouvrez l’application PDFgear sur votre ordinateur. Si vous ne l’avez pas encore installée, téléchargez et installez PDFgear depuis son site officiel.
Ouvrir un PDF avec PDFgear
Une fois PDFgear lancé, cliquez sur l’option ‘OUVRIR LE FICHIER‘ dans l’interface principale. Parcourez et sélectionnez le fichier PDF contenant une image numérisée pour l’ouvrir dans PDFgear.
Étape 2. Activer la fonctionnalité OCR
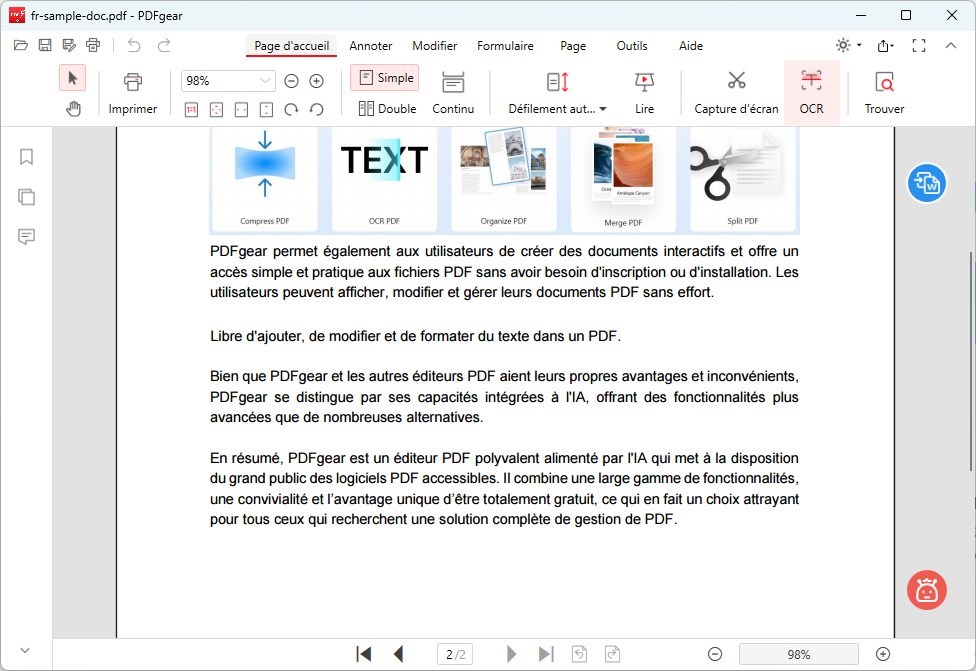
Recherchez la fonctionnalité OCR (Reconnaissance Optique de Caractères), qui se trouve généralement dans l’onglet “Page d’accueil“.
Ouvrir la fonctionnalité OCR dans PDFgear
Cliquez sur la fonctionnalité “OCR” pour activer la fonctionnalité de reconnaissance de texte.
Étape 3. Extraire du texte de l’image
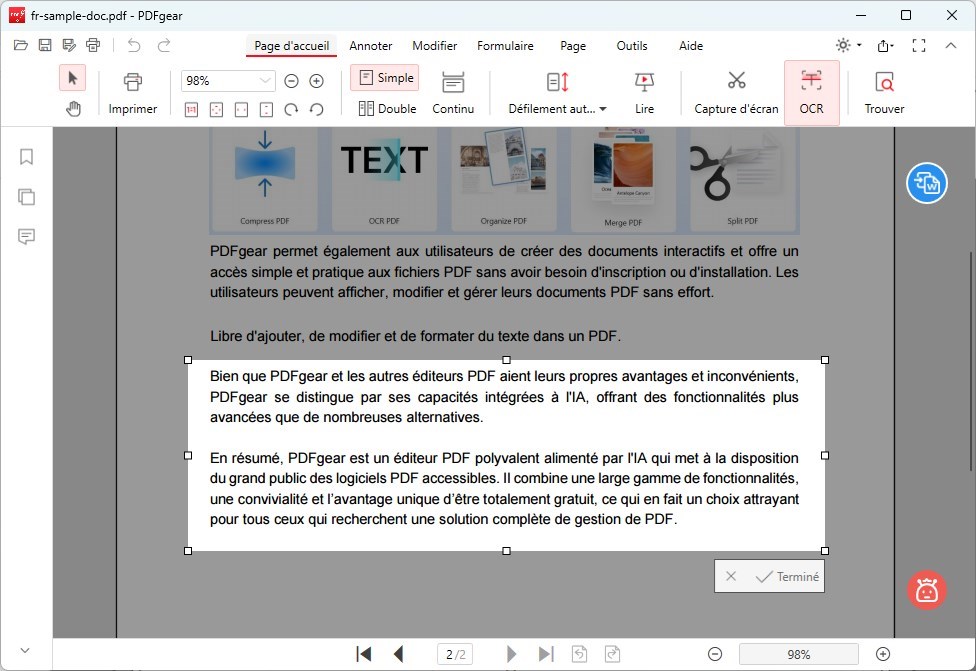
Avec votre souris, cliquez et faites glisser pour surligner/sélectionner les zones de texte dans l’image PDF que vous souhaitez extraire.
Relâchez le bouton de la souris une fois que vous avez sélectionné le texte désiré. Le texte sélectionné doit être souligné ou surligné.
Extraire du texte de l’image PDF
Cliquez sur le bouton “Terminé” ou une option similaire pour confirmer votre sélection de texte et procéder
Étape 4. Copier ou sauvegarder le texte extrait
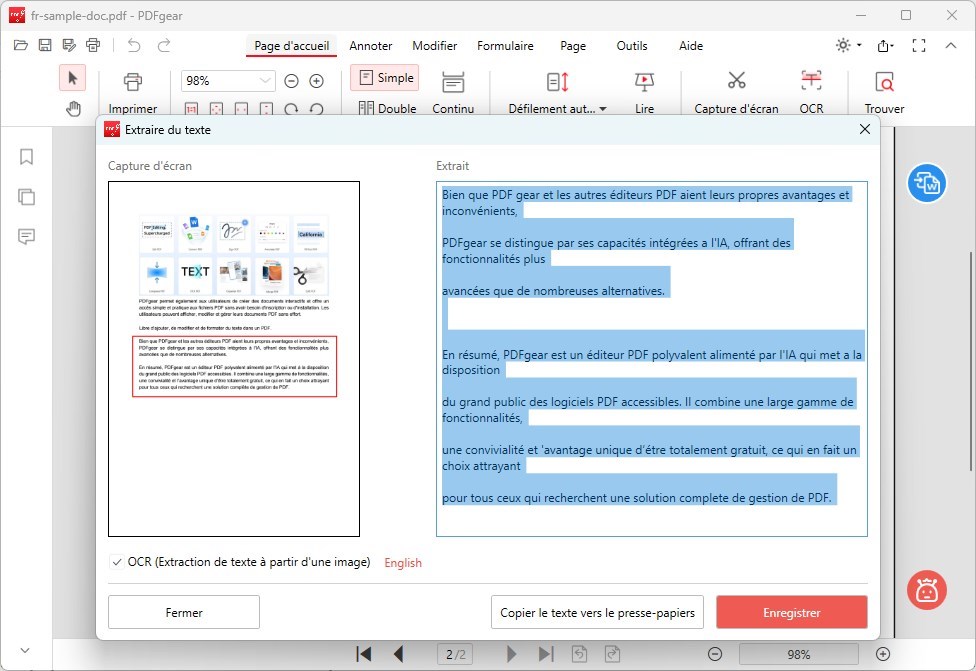
Après avoir sélectionné le texte et configuré les paramètres OCR (si applicable), choisissez comment vous souhaitez gérer le texte extrait :
Copier ou sauvegarder le texte extrait
Copier le texte vers le Presse-papiers : Cliquez sur le bouton “Copier” pour copier le texte extrait dans le presse-papiers. Vous pouvez ensuite le coller dans un éditeur de texte ou toute autre application.
Sauvegarder en tant que fichier texte (TXT) : Si vous préférez sauvegarder le texte extrait comme un fichier séparé, cliquez sur le bouton “Enregistrer“. Spécifiez le nom du fichier et l’emplacement où vous souhaitez enregistrer le fichier texte. Puis, cliquez sur “Enregistrer” pour enregistrer le texte extrait en tant que fichier TXT.
Extraire les données de facturation à partir d’un PDF
Lorsque vous saisissez manuellement des données dans le logiciel de base de données des factures, cela prend beaucoup de temps et des erreurs peuvent survenir durant le processus de saisie.
Tabula est un outil conçu pour extraire automatiquement des données de fichiers PDF en utilisant l’IA et la technologie de Reconnaissance Optique de Caractères (OCR). Il est spécialement conçu pour gérer les tableaux dans les PDFs, ce qui en fait un bon choix pour extraire des données structurées telles que les détails des factures.
Étape 1. Télécharger et installer Tabula
Rendez-vous sur le site de Tabula et téléchargez la version de Tabula compatible avec votre système d’exploitation (Windows, Mac, ou Linux).
Télécharger et installer Tabula
Suivez les instructions à l’écran pour installer Tabula sur votre ordinateur.
Étape 2. Télécharger le PDF de la facture dans Tabula
Lancez l’application : Ouvrez Tabula. Elle fonctionne généralement dans votre navigateur web comme un serveur local (par exemple, http://127.0.0.1:8080/).
Cliquer sur Parcourir dans Tabula
Cherchez une option pour “Parcourir” sur la page principale de Tabula. Cliquez sur cette icône, trouvez votre fichier PDF de facture et téléchargez-le.
Étape 3. Sélectionner les données à extraire
Une fois votre PDF téléchargé, Tabula vous montrera ce qu’il contient. Utilisez simplement votre souris pour dessiner un cadre autour du tableau ou des informations que vous souhaitez obtenir de la facture. Si la facture est sur plusieurs pages, vous pouvez choisir ce dont vous avez besoin sur chaque page.
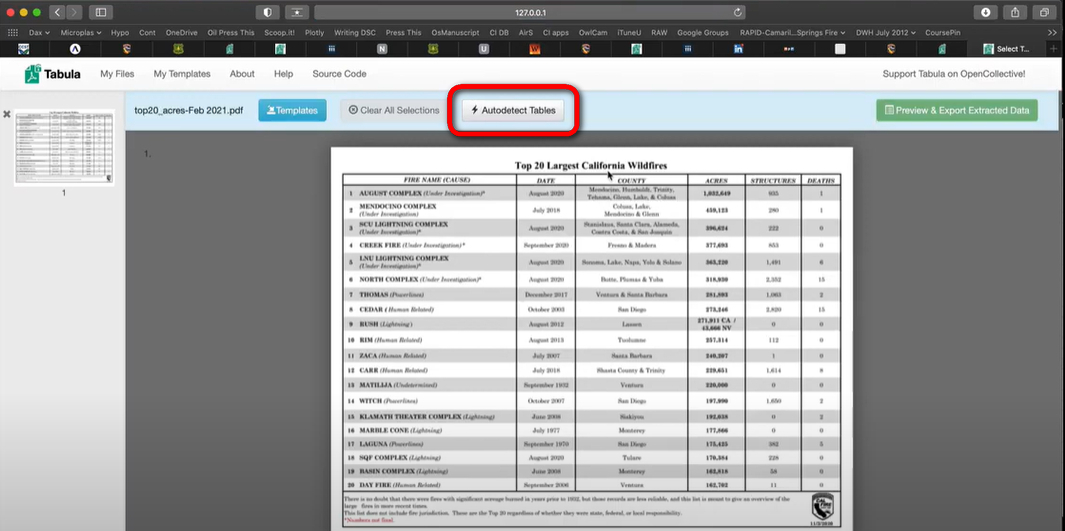
Détection automatique des tableaux dans Tabula
Une fois que vous avez choisi, vous pouvez vérifier si les informations sont correctes. Tabula vous permet de récupérer les données de différentes manières, comme en CSV ou Excel. Cliquez sur le bouton “Extraire les données” et choisissez le format que vous souhaitez.

Aperçu et exportation dans Tabula
Étape 4. Sauvegarder ou exporter les données
Une fois extraites, vous pouvez sauvegarder ou exporter les données sur votre ordinateur. Si vous avez choisi le format CSV, vous pouvez ouvrir le fichier dans n’importe quelle application de tableur comme Microsoft Excel ou Google Sheets pour un traitement ultérieur.
Définir le format d’exportation dans Tabula
Extraire les métadonnées d’un PDF
Les métadonnées PDF se réfèrent aux informations stockées dans un fichier PDF qui détaillent le document, telles que son titre, son auteur, son sujet et ses mots-clés.
Adobe Acrobat vous permet de visualiser et parfois d’éditer les métadonnées d’un fichier PDF. C’est la manière la plus simple pour les utilisateurs d’accéder aux métadonnées sans programmation.
Voici quelques étapes pour extraire les métadonnées d’un PDF :
Étape 1. Ouvrez le PDF dans Adobe Acrobat.
Étape 2. Accédez aux Propriétés du Document via le menu Fichier.
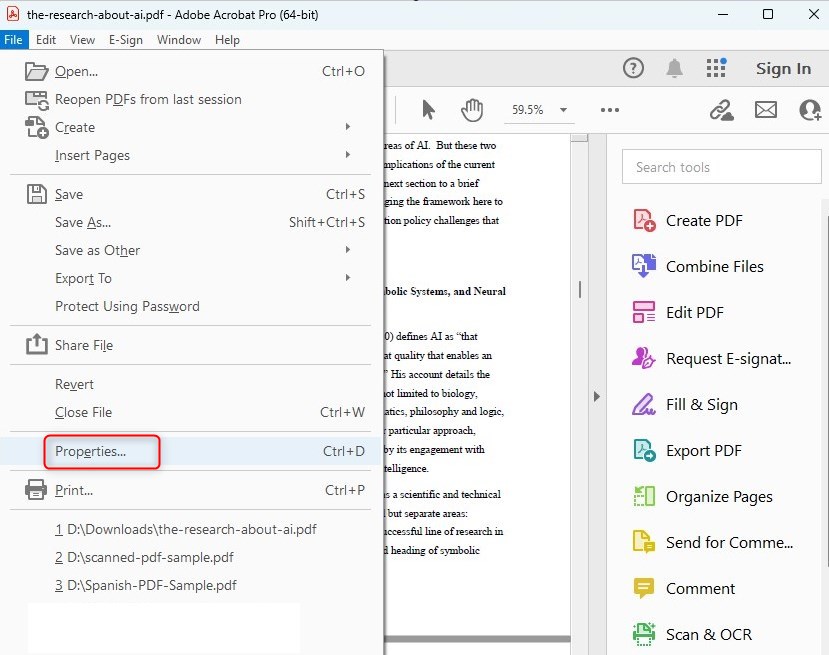
Ouvrir les Propriétés du Document dans Adobe
Étape 3. Visualisez les métadonnées dans l’onglet Description, où vous pouvez voir des champs comme Titre, Auteur, Sujet, et Mots-clés.
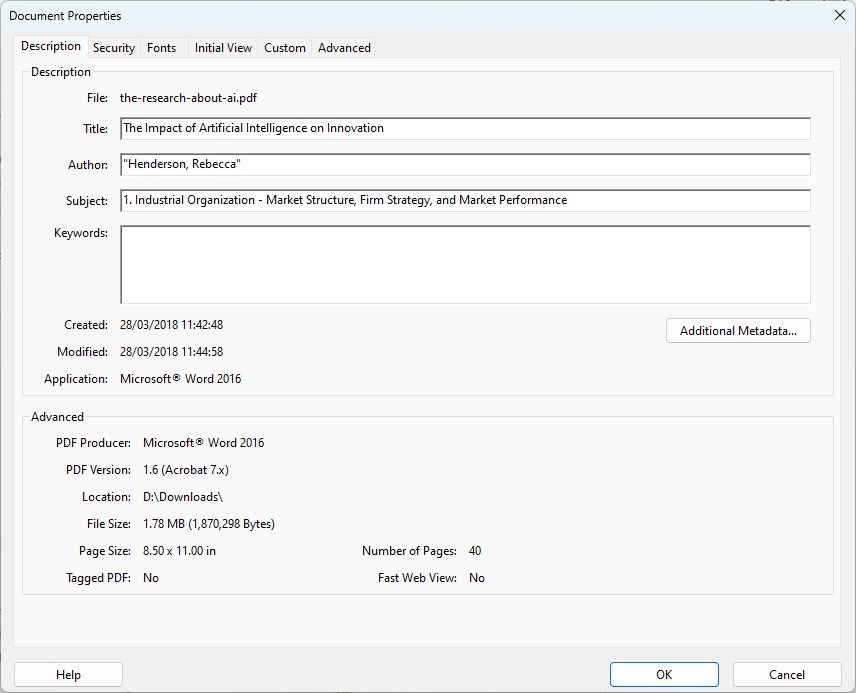
Visualiser les Métadonnées du Fichier PDF
Étape 4. Extrayez les informations souhaitées en sélectionnant et copiant le texte.
Sauvegardez les métadonnées extraites dans un document texte ou une application de prise de notes pour référence future.
Extraire des pages d’un PDF
Pour ceux qui ont besoin d’extraire des pages spécifiques d’un document PDF existant pour créer une nouvelle version plus raffinée du document original. PDFgear offre un outil de division de PDF pour diviser un fichier PDF par plages de pages ou extraire toutes les pages du PDF en plusieurs fichiers PDF.
Voici comment extraire des pages de PDF et créer plusieurs PDF à partir d’un seul :
Étape 1. Tout d’abord, téléchargez et installez PDFgear sur votre Windows ou Mac. Lancez Adobe Acrobat DC sur votre ordinateur.
Ouvrir un PDF avec PDFgear
Ouvrez le fichier PDF à partir duquel vous souhaitez extraire des pages en cliquant sur “Ouvrir le fichier” et en sélectionnant le document PDF.
Étape 2. Une fois votre PDF ouvert, cliquez sur l’onglet “Page” dans la barre de menu supérieure.
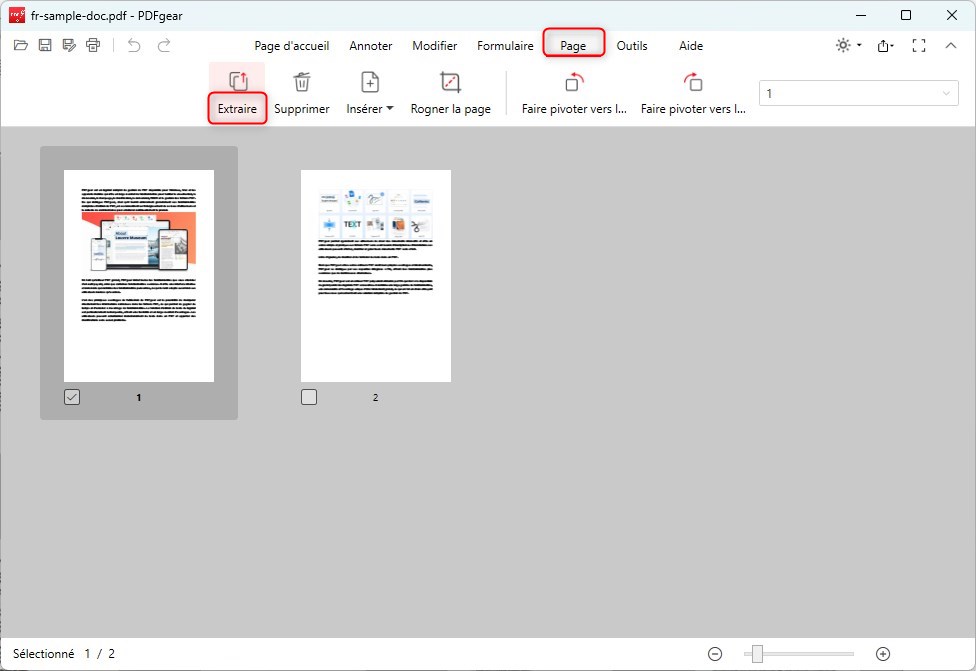
Option d’extraction de page dans PDFgear
Sous l’onglet “Pages“, vous verrez des options pour manipuler vos pages PDF, y compris les extraire.
Étape 3. Vous pouvez sélectionner les pages que vous souhaitez extraire. Vous pouvez cliquer sur des pages individuelles, ou sélectionner plusieurs pages.
Étape 4. Après avoir sélectionné les pages, cliquez sur le bouton “Extraire” sous l’onglet “Pages“.
Une nouvelle boîte de dialogue apparaîtra, vous donnant l’option d’extraire les pages sélectionnées dans un fichier PDF séparé. Vous pouvez également supprimer les pages sélectionnées du document original après l’extraction en cochant l’option “Supprimer les pages sélectionnées après extraction“.
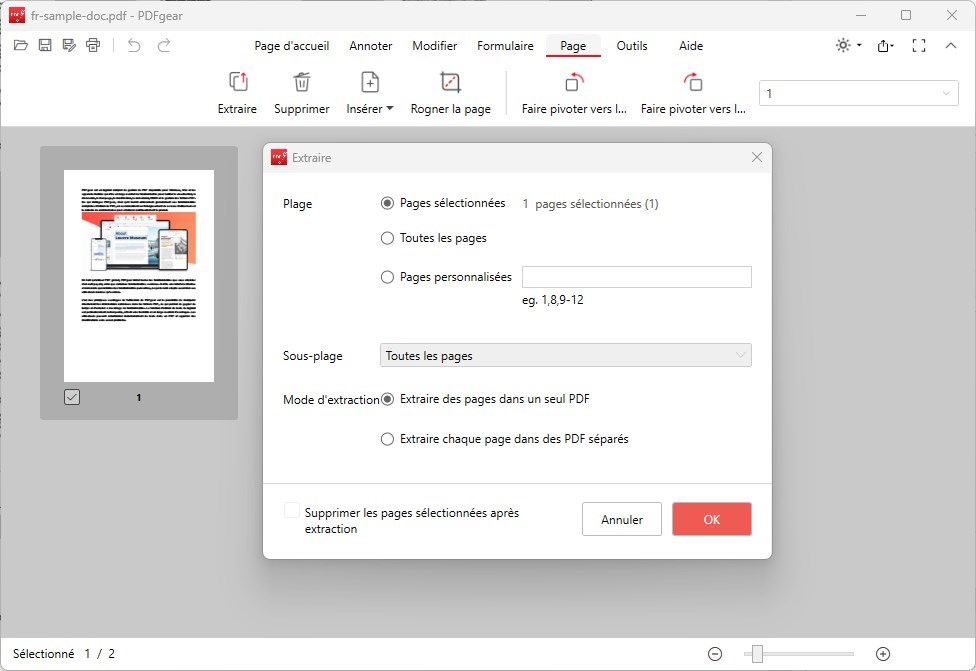
Extraire des pages de PDF avec PDFgear
Cliquez sur “OK” pour extraire les pages sélectionnées dans un nouveau document PDF.
Étape 5. Vous serez automatiquement redirigé vers l’Explorateur de fichiers. De là, vous pouvez choisir de sauvegarder les pages PDF extraites à l’emplacement souhaité et spécifier un nom de fichier pour le nouveau document.
Extraire des images d’un PDF
Les images intégrées dans les PDF ne sont pas fixées de manière permanente et peuvent être extraites pour être utilisées ailleurs. Que vous ayez besoin d’une seule image ou de plusieurs images d’un document, vous pouvez utiliser des outils logiciels pour les extraire facilement.
En utilisant un extracteur d’images PDF, les images sont extraites dans leur format et qualité originaux. Et aucune filigrane n’est ajoutée aux images extraites.
Suivez ces étapes pour extraire des images d’un PDF en masse :
Étape 1. Ouvrez votre navigateur web et naviguez jusqu’à la page d’extraction d’images de PDF Candy.
Étape 2. Vous pouvez télécharger le fichier PDF à partir duquel vous souhaitez extraire des images de plusieurs manières :
Glissez simplement le fichier PDF de votre ordinateur et déposez-le dans la zone désignée sur la page web.

Ajouter un PDF à l’extracteur d’images en ligne
Cliquez sur le bouton “AJOUTER FICHIER” pour ouvrir une boîte de dialogue de fichier, puis naviguez vers et sélectionnez le fichier PDF que vous souhaitez utiliser.
Si votre PDF est stocké sur Google Drive ou Dropbox, vous pouvez le télécharger directement depuis ces services en cliquant sur les icônes respectives.
Étape 3. Une fois que vous avez téléchargé le PDF, PDF Candy commencera automatiquement le processus d’extraction d’images du document PDF. Vous n’avez rien à faire pendant cette étape ; l’outil gère tout.
Étape 4. Après que le processus d’extraction soit terminé, PDF Candy vous fournira une archive ZIP contenant toutes les images extraites du PDF.
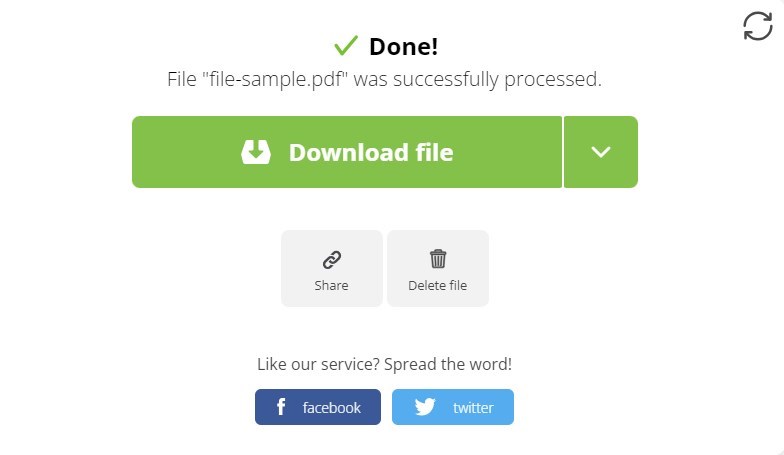
Télécharger les images extraites en ligne
Cliquez sur le bouton “Télécharger” pour enregistrer le fichier ZIP sur votre ordinateur.
Si vous préférez, vous pouvez également enregistrer des images individuelles en les prévisualisant et en sélectionnant celles spécifiques pour le téléchargement.
Foire aux questions
Comment extraire des informations d’un PDF avec Python ?
Python dispose de plusieurs bibliothèques pour traiter les PDFs, telles que PyPDF2, PDFMiner et PyMuPDF. Vous pouvez les utiliser pour obtenir du texte, des informations sur le fichier, et parfois même des images des PDFs. La bibliothèque que vous choisissez dépend de ce dont votre projet a besoin, comme si vous avez besoin de conserver le formatage du texte détaillé, d’extraire des images, ou de garantir une exécution rapide.
Est-il possible d’extraire des tableaux des documents PDF ?
Oui, l’extraction de tableaux des documents PDF peut être réalisée à l’aide de Tabula, Camelot et ExtractTable. Ces outils analysent la structure du PDF et tentent de reconnaître et d’extraire les données tabulaires dans des formats tels que CSV ou Excel, facilitant ainsi le travail avec les données.
Comment extraire un résumé d’un PDF avec l’IA ?
PDFgear dispose d’un outil IA qui peut vous aider à résumer facilement un PDF. Ouvrez un PDF dans PDFgear après avoir téléchargé et installé ce logiciel. Cliquez sur l’icône Copilot pour ouvrir l’outil IA. Envoyez la commande pour demander au Copilot de résumer votre PDF. Vous obtiendrez un résumé en quelques secondes.
Conclusion
Les PDF stockent des textes, des données, des métadonnées, des pages et des images précieuses qui peuvent être extraites à l’aide de diverses méthodes, allant de la manipulation manuelle aux parseurs IA automatisés. Ces méthodes mentionnées dans ce post fournissent des solutions simples pour extraire des informations des PDFs pour une utilisation future.
PDFgear est l’un des meilleurs logiciels de montage IA. Il fournit divers outils pour extraire des informations telles que le texte, les pages et les résumés des PDFs. Téléchargez-le pour essayer ses fonctionnalités et optimiser votre flux de travail PDF.