Estrazione delle informazioni: come estrarre testo, dati, pagina e immagine da un PDF

Sommario :
Potresti essere interessato a estrarre dati, pagine e immagini da un documento PDF per riutilizzarli. In questo post, impareremo come estrarre informazioni da un PDF con una guida completa.
Indice

Estrarre informazioni da PDF
Molti rapporti, documenti di ricerca e set di dati vengono distribuiti come PDF. Passare manualmente attraverso centinaia di pagine per trovare informazioni rilevanti è estremamente noioso e richiede molto tempo.
Vuoi sapere come estrarre informazioni da un PDF? Il post fornisce una guida dettagliata su come fare ogni tipo di estrazione. È utile per chiunque voglia ottenere informazioni dai PDF per scuola, lavoro o uso personale.
Estrai testo dall’immagine PDF
PDFgear è un editor PDF AI gratuito, che offre molti strumenti avanzati di modifica dei PDF che consentono agli utenti di sostituire, rimuovere e aggiungere qualsiasi testo in un PDF.
Con la sua funzionalità OCR integrata, PDFgear può aiutarti a estrarre testo da PDF basati su immagini, anche se non puoi selezionarlo. Funziona in oltre 10 lingue come inglese, francese e italiano. Puoi anche selezionare qualsiasi parte di una pagina PDF per estrarre il testo usando OCR.
Passo 1. Apri un documento scansionato
Apri l’applicazione PDFgear sul tuo computer. Se non l’hai ancora installata, scarica e installa PDFgear dal suo sito ufficiale.
Apri un PDF con PDFgear
Una volta lanciato PDFgear, clicca sull’opzione ‘Apri file‘ nell’interfaccia principale. Sfoglia e seleziona il file PDF contenente un’immagine scansionata per aprirlo in PDFgear.
Passo 2. Attiva la funzionalità OCR
Cerca la funzionalità OCR (Riconoscimento Ottico dei Caratteri), che si trova tipicamente nella scheda “Pagina iniziale“.
Apri la funzionalità OCR in PDFgear
Clicca sulla funzionalità “OCR” per attivare la funzionalità di riconoscimento del testo.
Passo 3. Estrai il testo dall’immagine
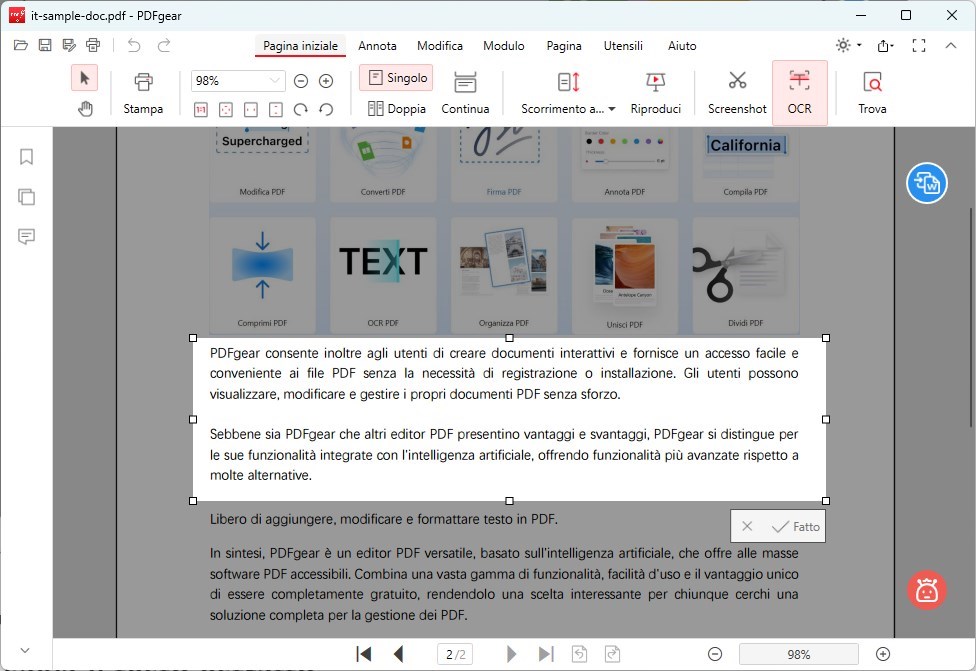
Usando il mouse, clicca e trascina per evidenziare/selezionare le aree di testo all’interno dell’immagine PDF da cui vuoi estrarre il testo.
Rilascia il pulsante del mouse una volta selezionato il testo desiderato. Il testo selezionato dovrebbe essere delineato o evidenziato.
Estrai testo dall’immagine PDF
Clicca sul pulsante “Fatto” o su un’opzione simile per confermare la tua selezione di testo e procedere
Passo 4. Copia o salva il testo estratto
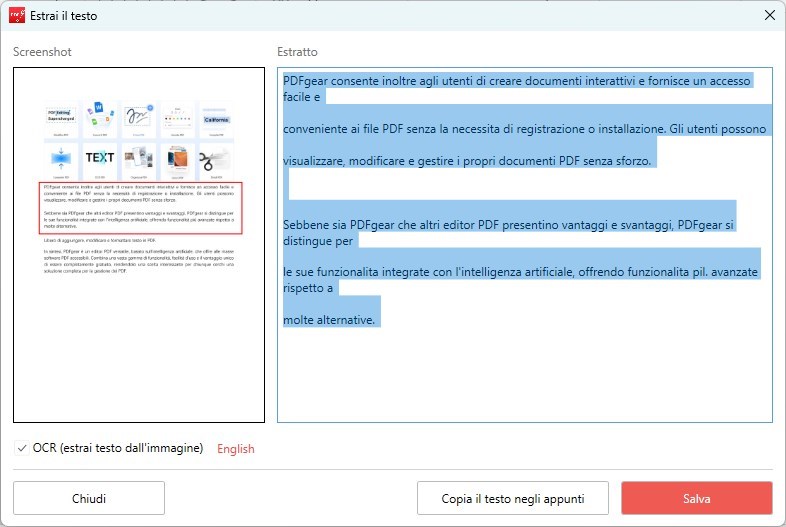
Dopo aver selezionato il testo e configurato le impostazioni OCR (se applicabile), scegli come vuoi gestire il testo estratto:
Copia o salva il testo estratto
Copia negli Appunti: Clicca sul pulsante “Copia” per copiare il testo estratto negli appunti. Puoi poi incollarlo in un editor di testo o in qualsiasi altra applicazione.
Salva come file di testo (TXT): Se preferisci salvare il testo estratto come file separato, clicca sul pulsante “Salva“. Specifica il nome del file e il luogo in cui desideri salvarlo. Poi, clicca “Salva” per salvare il testo estratto come file TXT.
Estrai dati fattura da PDF
Quando inserisci manualmente i dati nel software del database delle fatture, ci vuole molto tempo e potrebbero esserci alcuni errori durante il processo di inserimento dei dati.
Tabula è uno strumento progettato per estrarre automaticamente dati dai file PDF utilizzando l’IA e la tecnologia di Riconoscimento Ottico dei Caratteri (OCR). È specificamente progettato per gestire tabelle all’interno dei PDF, rendendolo una buona scelta per estrarre dati strutturati come i dettagli delle fatture.
Passo 1. Scarica e installa Tabula
Vai al sito di Tabula e scarica la versione di Tabula compatibile con il tuo sistema operativo (Windows, Mac o Linux).
Scarica e installa Tabula
Segui le istruzioni a schermo per installare Tabula sul tuo computer.
Passo 2. Carica il PDF della fattura in Tabula
Avvia l’applicazione: Apri Tabula. Tipicamente funziona nel tuo browser web come un server locale (ad es., http://127.0.0.1:8080/).
Clicca Sfoglia in Tabula
Cerca un’opzione per “Sfoglia” nella pagina principale di Tabula. Clicca su questa icona, trova il file PDF della tua fattura e caricarlo.
Passo 3. Seleziona i dati da estrarre
Una volta caricato il tuo PDF, Tabula mostrerà cosa c’è dentro. Usa semplicemente il mouse per disegnare un riquadro intorno alla tabella o alle informazioni che desideri dalla fattura. Se la fattura è su più di una pagina, puoi scegliere ciò che ti serve da ogni pagina.
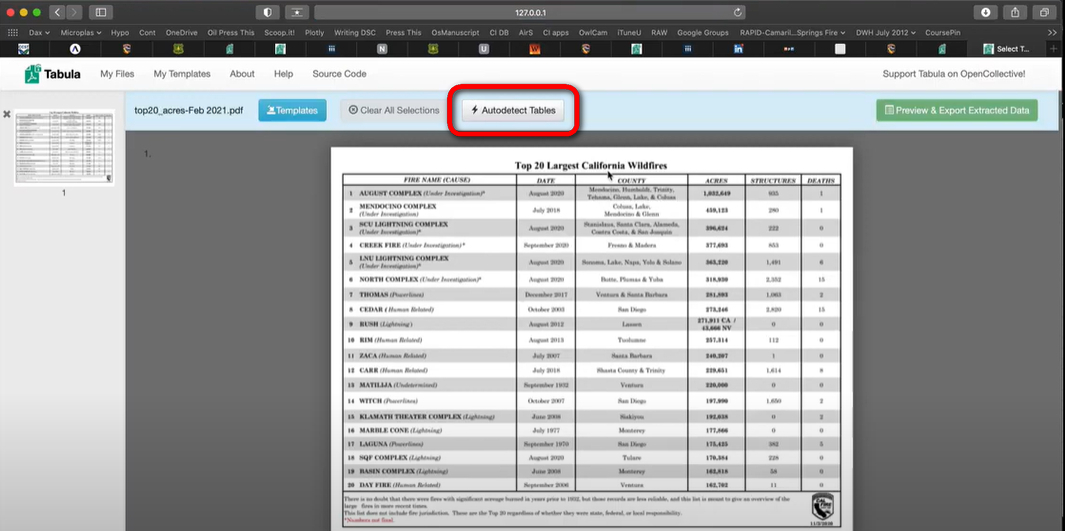
Rilevamento automatico delle tabelle in Tabula
Una volta scelto, puoi verificare se le informazioni sono corrette. Tabula ti permette di ottenere i dati in diversi modi, come CSV o Excel. Clicca sul pulsante “Estrai Dati” e scegli il formato che desideri.

Anteprima ed esportazione in Tabula
Passo 4. Salva o esporta i dati
Una volta estratti, puoi salvare o esportare i dati sul tuo computer. Se hai scelto CSV, puoi aprire il file in qualsiasi applicazione di fogli di calcolo come Microsoft Excel o Google Sheets per ulteriori elaborazioni.
Imposta formato di esportazione in Tabula
Estrai i metadati da PDF
I metadati PDF si riferiscono alle informazioni memorizzate all’interno di un file PDF che dettagliano il documento, come il suo titolo, autore, argomento e parole chiave.
Adobe Acrobat consente di visualizzare e talvolta modificare i metadati di un file PDF. Questo è il modo più semplice per gli utenti di accedere ai metadati senza programmazione.
Ecco alcuni passaggi per estrarre i metadati PDF:
Passo 1. Apri il PDF in Adobe Acrobat.
Passo 2. Accedi alle Proprietà del Documento tramite il menu File.
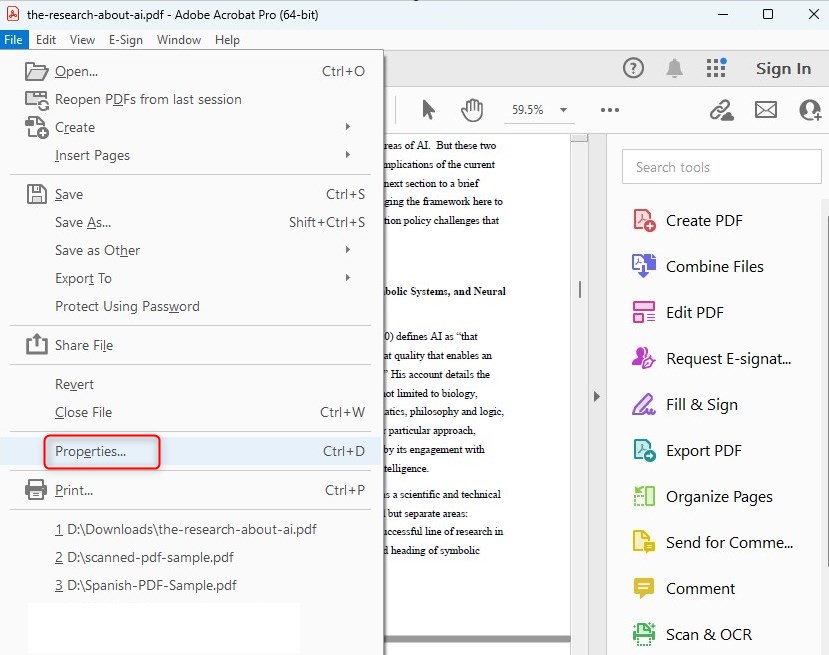
Apri Proprietà Documento in Adobe
Passo 3. Visualizza i metadati nella scheda Descrizione, dove puoi vedere campi come Titolo, Autore, Argomento e Parole chiave.
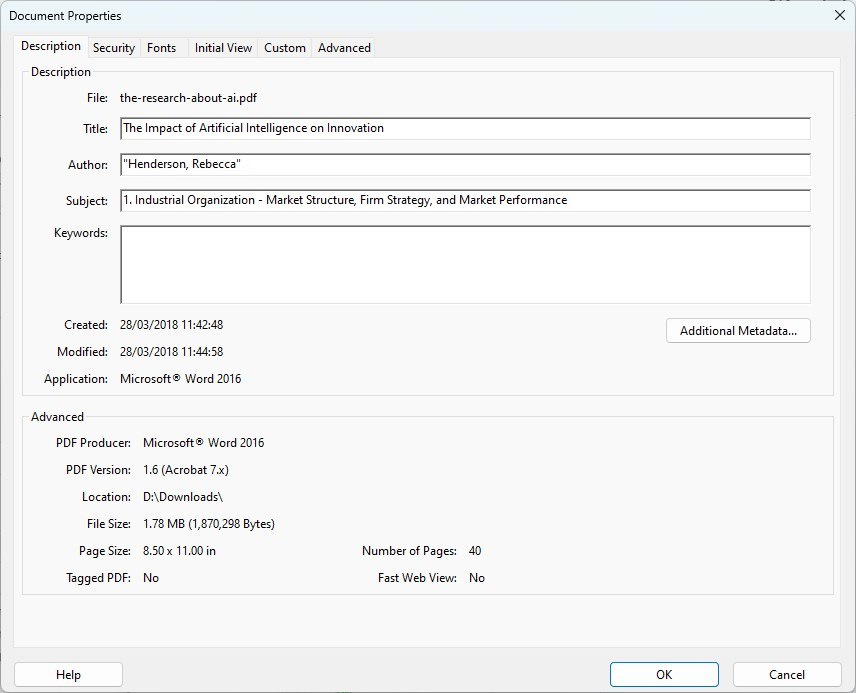
Visualizza i Metadati del File PDF
Passo 4. Estrai le informazioni desiderate selezionando e copiando il testo.
Salva i metadati estratti in un documento di testo o app di note per riferimenti futuri.
Estrai pagine da PDF
Per coloro che hanno bisogno di estrarre pagine specifiche da un documento PDF esistente per creare una versione nuova e più raffinata del documento originale. PDFgear offre uno strumento di divisione PDF per dividere un file PDF per intervalli di pagine o estrarre tutte le pagine del PDF in più file PDF.
Ecco come estrarre pagine PDF e creare più PDF da uno:
Passo 1. Prima, scarica e installa PDFgear sul tuo Windows o Mac. Avvia Adobe Acrobat DC sul tuo computer.
Apri un PDF con PDFgear
Apri il file PDF dal quale desideri estrarre le pagine cliccando su “Apri File” e selezionando il documento PDF.
Passo 2. Una volta aperto il tuo PDF, clicca sulla scheda “Pagina” nella barra dei menu in alto.
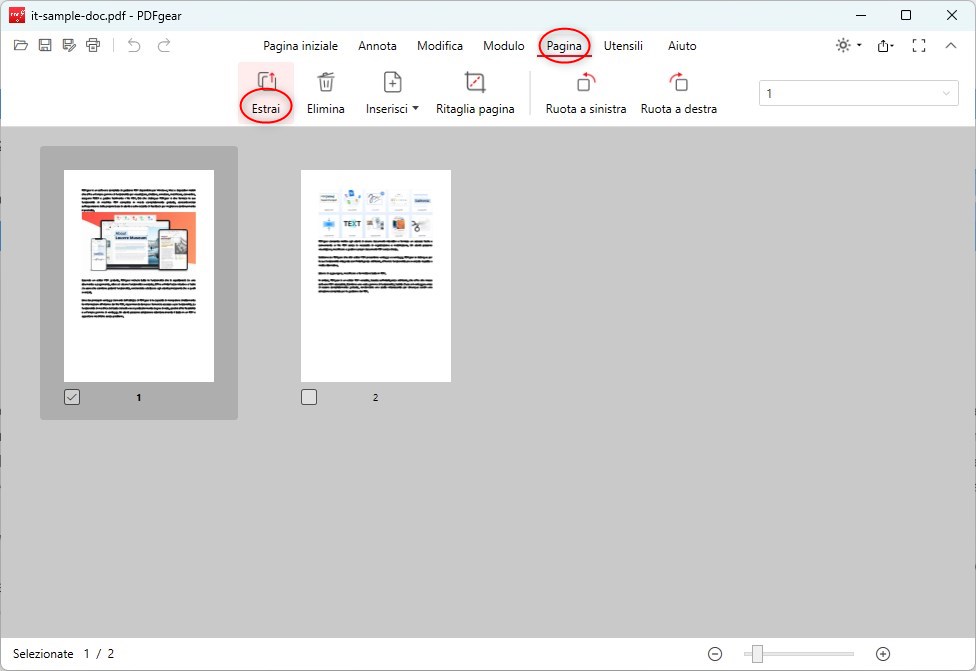
Opzione Estrai Pagina in PDFgear
Sotto la scheda “Pagine“, vedrai opzioni per manipolare le tue pagine PDF, inclusa l’estrazione.
Passo 3. Puoi selezionare le pagine che desideri estrarre. Puoi cliccare su pagine individuali o selezionare più pagine contemporaneamente.
Passo 4. Dopo aver selezionato le pagine, clicca sul pulsante “Estrai” sotto la scheda “Pagine“.
Apparirà una nuova finestra di dialogo, dandoti l’opzione di estrarre le pagine selezionate come un file PDF separato. Puoi anche cancellare le pagine selezionate dal documento originale dopo l’estrazione selezionando l’opzione “Elimina le pagine selezionate dopo l’estrazione“.
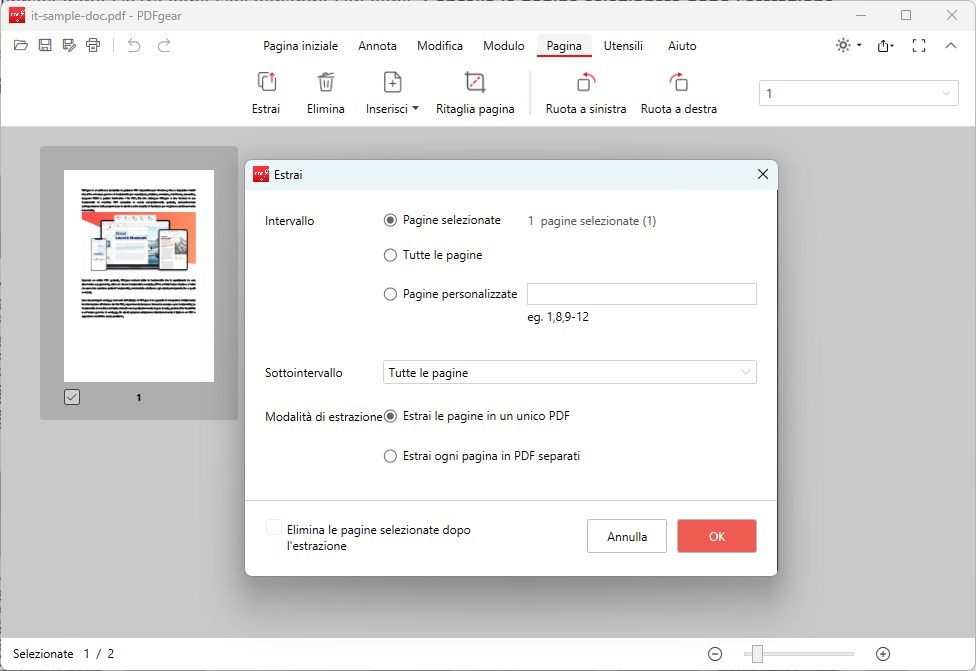
Estrai pagine da PDF con PDFgear
Clicca su “OK” per estrarre le pagine selezionate in un nuovo documento PDF.
Passo 5. Passerai automaticamente all’Esplora File. Da lì, puoi scegliere di salvare le pagine PDF estratte nella posizione desiderata e specificare un nome file per il nuovo documento.
Estrai immagini da PDF
Le immagini incorporate nei PDF non sono fissate permanentemente e possono essere estratte per essere utilizzate altrove. Che tu abbia bisogno di una singola immagine o di più immagini da un documento, puoi utilizzare strumenti software per estrarle facilmente.
Utilizzando un estrazione di immagini PDF, le immagini vengono estratte nel loro formato e qualità originali. E non vengono aggiunte filigrane alle immagini estratte.
Segui questi passaggi per estrarre immagini da un PDF in blocco:
Passo 1. Apri il tuo browser web e naviga alla pagina di estrazione immagini di PDF Candy.
Passo 2. Puoi caricare il file PDF da cui desideri estrarre le immagini in diversi modi:
Semplicemente trascina il file PDF dal tuo computer e rilascialo nell’area designata sulla pagina web.

Aggiungi PDF all’Estrattore di Immagini Online
Clicca sul pulsante “AGGIUNGI FILE” per aprire una finestra di dialogo del file, quindi naviga e seleziona il file PDF che desideri utilizzare.
Se il tuo PDF è memorizzato su Google Drive o Dropbox, puoi caricarlo direttamente da questi servizi cliccando sulle icone corrispondenti.
Passo 3. Una volta caricato il PDF, PDF Candy inizierà automaticamente il processo di estrazione delle immagini dal documento PDF. Non c’è bisogno che tu faccia nulla durante questo passaggio; lo strumento gestisce tutto.
Passo 4. Dopo che il processo di estrazione è completato, PDF Candy ti fornirà un archivio ZIP contenente tutte le immagini estratte dal PDF.
Scarica le Immagini Estratte Online
Clicca sul pulsante “Scarica” per salvare il file ZIP sul tuo computer.
Se preferisci, puoi anche salvare singole immagini anteprimaandole e selezionando quelle specifiche per il download.
Domande frequenti
Come estrarre informazioni da un PDF usando Python?
Python dispone di alcune librerie per gestire i PDF, come PyPDF2, PDFMiner e PyMuPDF. Puoi utilizzarle per ottenere testo, informazioni sul file e talvolta anche immagini dai PDF. La libreria che scegli dipende da cosa necessita il tuo progetto, come se hai bisogno di mantenere il formato del testo dettagliato, estrarre immagini o assicurare che le cose funzionino velocemente.
È possibile estrarre tabelle dai documenti PDF?
Sì, l’estrazione di tabelle dai documenti PDF può essere effettuata utilizzando Tabula, Camelot e ExtractTable. Questi strumenti analizzano la struttura del PDF e tentano di riconoscere ed estrarre dati tabellari in formati come CSV o Excel, facilitando il lavoro con i dati.
Come estrarre un riassunto da un PDF con l’IA?
PDFgear dispone di uno strumento IA che può aiutarti a riassumere un PDF con facilità. Apri un PDF in PDFgear dopo aver scaricato e installato questo software. Clicca sull’icona Copilota per aprire lo strumento IA. Invia il comando per chiedere al Copilota di riassumere il tuo PDF. Riceverai un riassunto in pochi secondi.
Conclusione
I PDF conservano testi, dati, metadati, pagine e immagini preziose che possono essere estratti utilizzando vari metodi, da manuali a parser IA automatizzati. Questi metodi menzionati in questo post forniscono soluzioni semplici per estrarre informazioni dai PDF per un uso futuro.
PDFgear è uno dei migliori software di editing IA. Fornisce vari strumenti per estrarre informazioni come testo, pagine e riassunti dai PDF. Scaricalo per provare le sue funzionalità e semplificare il tuo flusso di lavoro con i PDF.