Extracción de información: Cómo extraer texto, datos, páginas e imágenes de un PDF

Resumen :
Podrías estar interesado en extraer datos, páginas e imágenes de un documento PDF para reutilizarlos. En este artículo, aprenderemos cómo extraer información de un PDF con una guía completa.
Tabla de Contenido

cómo extraer información de PDF
Muchos informes, trabajos de investigación y conjuntos de datos se distribuyen en formato PDF. Revisar manualmente cientos de páginas para encontrar información relevante es extremadamente tedioso y consume mucho tiempo.
¿Quieres saber cómo extraer información de un PDF? La publicación ofrece una guía detallada sobre cómo realizar cada tipo de extracción. Es útil para cualquiera que quiera obtener información de PDFs para la escuela, el trabajo o uso personal.
Extraer Texto de una Imagen en PDF
PDFgear es un editor de PDFs AI gratuito, que ofrece muchas herramientas avanzadas de edición de PDF que permiten a los usuarios reemplazar, eliminar y añadir cualquier texto en un PDF.
Con su función OCR integrada, PDFgear puede ayudarte a extraer texto de PDFs basados en imágenes, incluso si no puedes seleccionarlo. Funciona en más de 10 idiomas como inglés, francés e italiano. También puedes seleccionar cualquier parte de una página de PDF para extraer texto usando OCR.
Paso 1. Abrir un Documento Escaneado
Abre la aplicación PDFgear en tu computador. Si aún no la has instalado, descarga e instala PDFgear desde su sitio web oficial.
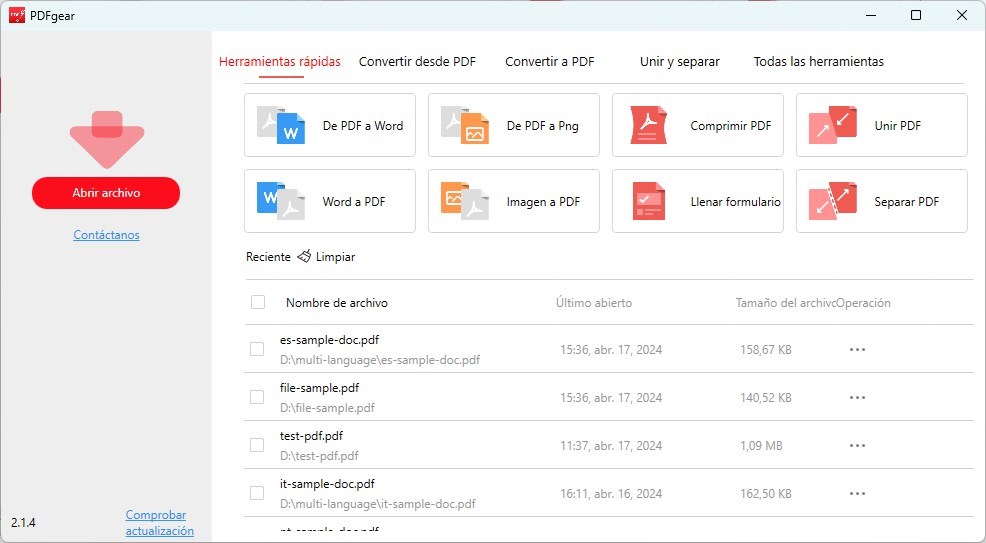
Abrir un PDF con PDFgear
Una vez que se haya lanzado PDFgear, haz clic en la opción ‘Abrir Archivo‘ en la interfaz principal. Navega y selecciona el archivo PDF que contiene una imagen escaneada para abrirlo en PDFgear.
Paso 2. Activar la Función OCR
Busca la función OCR (Reconocimiento Óptico de Caracteres), que generalmente se encuentra en la pestaña “Página principal”.
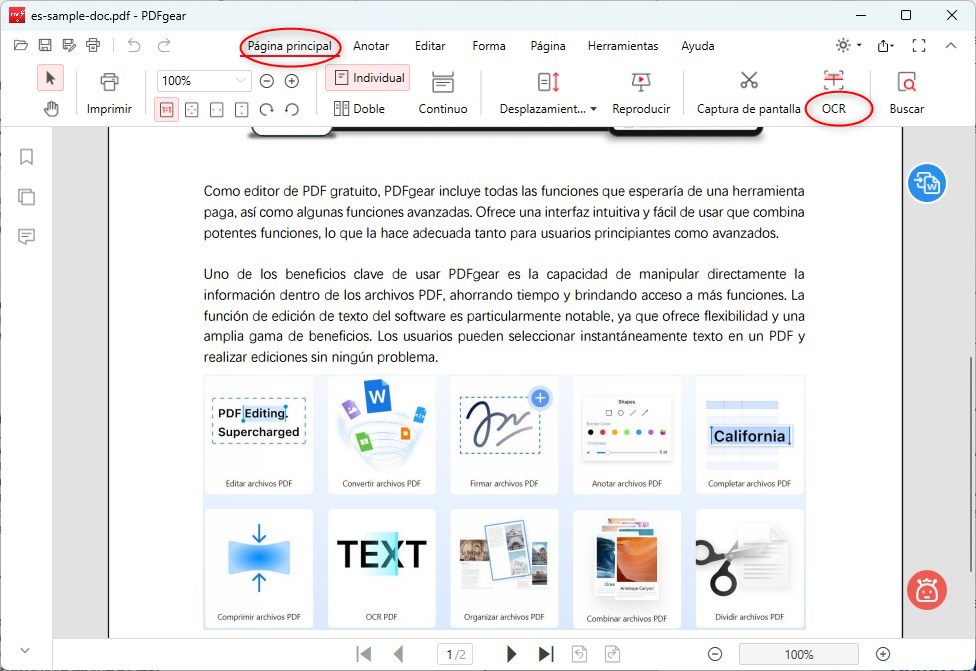
Abrir la Función OCR en PDFgear
Haz clic en la función “OCR” para activar la funcionalidad de reconocimiento de texto.
Paso 3. Extraer Texto de la Imagen
Usa tu ratón para hacer clic y arrastrar para resaltar/seleccionar las áreas de texto dentro de la imagen del PDF de las que quieres extraer texto.
Suelta el botón del ratón una vez que hayas seleccionado el texto deseado. El texto seleccionado debe estar delineado o resaltado.
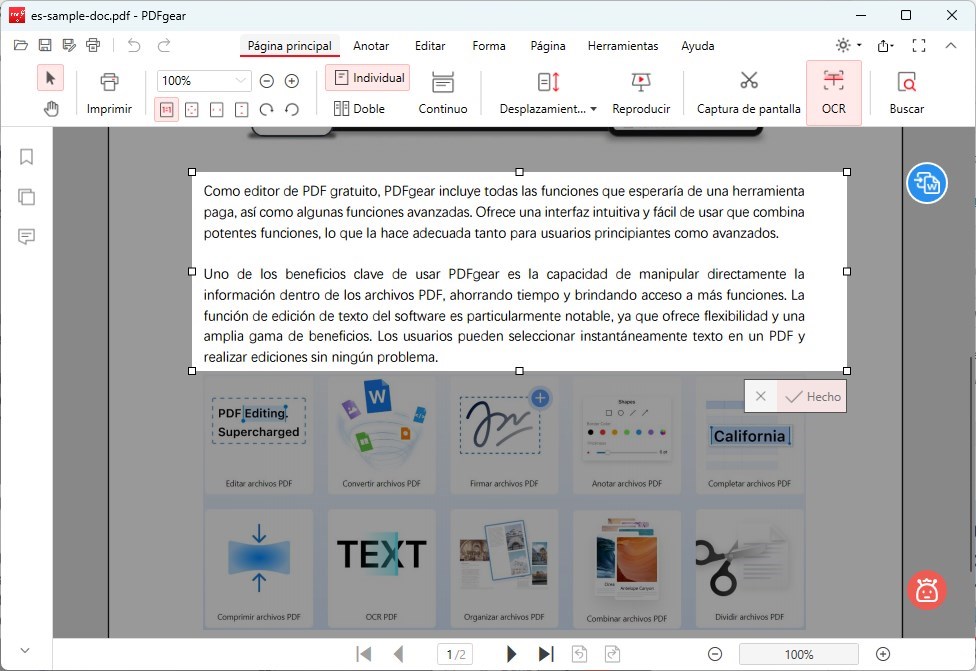
Extraer Texto de una Imagen en PDF
Haz clic en el botón “Hecho” o una opción similar para confirmar tu selección de texto y proceder
Paso 4. Copiar o Guardar el Texto Extraído
Después de seleccionar el texto y configurar los ajustes de OCR (si aplica), elige cómo deseas manejar el texto extraído:
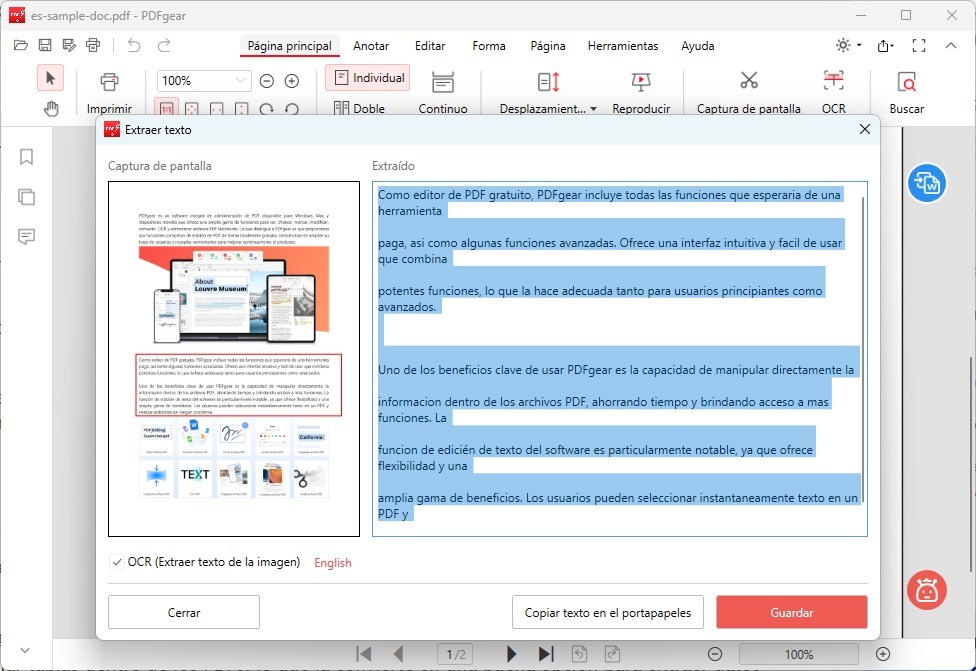
Copiar o Guardar el Texto Extraído
Copiar al Portapapeles: Haz clic en el botón “Copiar” para copiar el texto extraído al portapapeles. Luego, puedes pegarlo en un editor de texto u otra aplicación.
Guardar como Archivo de Texto (TXT): Si prefieres guardar el texto extraído como un archivo separado, haz clic en el botón “Guardar“. Especifica el nombre y la ubicación del archivo donde deseas guardar el texto. Luego, haz clic en “Guardar” para guardar el texto extraído como un archivo TXT.
Extraer Datos de Facturas de un PDF
Cuando introduces datos manualmente en el software de base de datos de facturas, se tarda mucho tiempo y podrían ocurrir algunos errores durante el proceso de entrada de datos.
Tabula es una herramienta diseñada para extraer datos de archivos PDF automáticamente utilizando IA y tecnología de Reconocimiento Óptico de Caracteres (OCR). Está específicamente diseñada para manejar tablas dentro de los PDFs, lo que la convierte en una buena opción para extraer datos estructurados como detalles de facturas.
Paso 1. Descargar e Instalar Tabula
Ve al sitio web de Tabula y descarga la versión de Tabula que sea compatible con tu sistema operativo (Windows, Mac o Linux).
Descargar e Instalar Tabula
Sigue las instrucciones en pantalla para instalar Tabula en tu computadora.
Paso 2. Subir el PDF de la Factura en Tabula
Inicia la aplicación: Abre Tabula. Generalmente funciona en tu navegador web como un servidor local (por ejemplo, http://127.0.0.1:8080/).
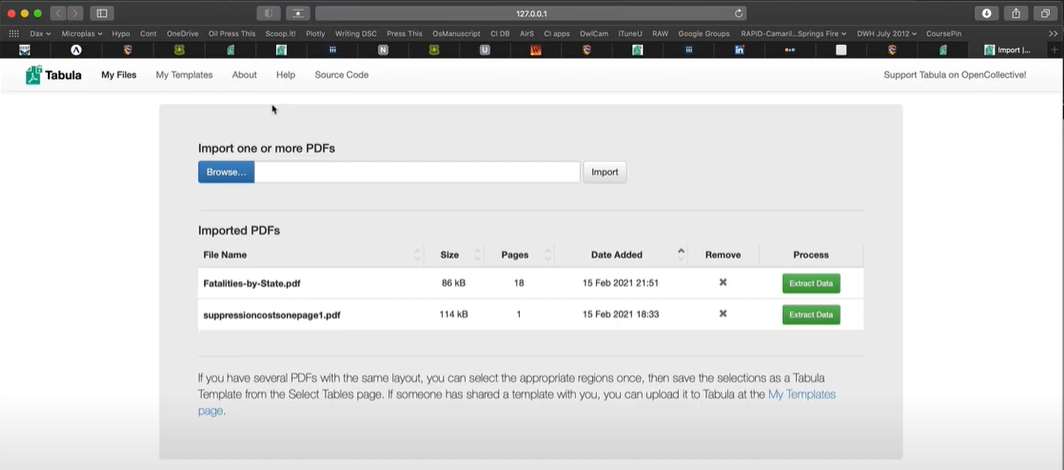
Haz Clic en Examinar en Tabula
Busca una opción para “Examinar” en la página principal de Tabula. Haz clic en este ícono, encuentra tu archivo de factura en PDF y súbelo.
Paso 3. Seleccionar los Datos a Extraer
Una vez que hayas subido tu PDF, Tabula mostrará lo que contiene. Solo usa tu ratón para dibujar un cuadro alrededor de la tabla o la información que deseas de la factura. Si la factura está en más de una página, puedes elegir lo que necesitas de cada página.
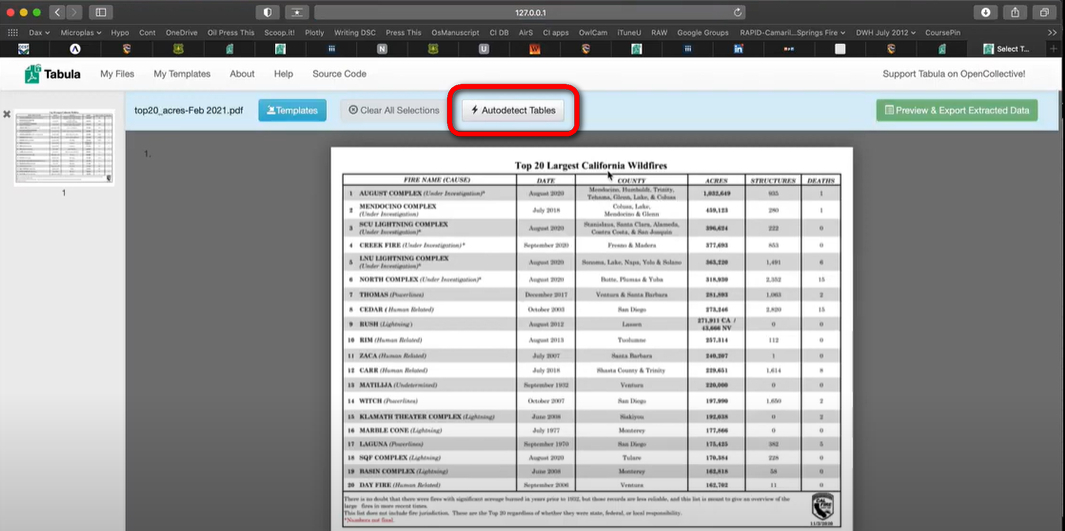
Detección Automática de Tablas en Tabula
Una vez que hayas elegido, puedes verificar si la información es correcta. Tabula te permite obtener los datos de diferentes maneras, como CSV o Excel. Haz clic en el botón “Extraer Datos” y elige el formato que deseas.

Vista Previa y Exportar en Tabula
Paso 4. Guardar o Exportar los Datos
Una vez extraídos, puedes guardar o exportar los datos a tu computadora. Si elegiste CSV, puedes abrir el archivo en cualquier aplicación de hoja de cálculo como Microsoft Excel o Google Sheets para su posterior procesamiento.
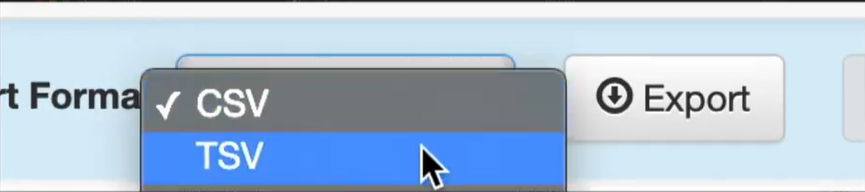
Establecer Formato de Exportación en Tabula
Extraer Metadatos de PDF
Los metadatos de PDF se refieren a la información almacenada dentro de un archivo PDF que detalla el documento, como su título, autor, tema y palabras clave.
Adobe Acrobat te permite ver y, a veces, editar los metadatos de un archivo PDF. Esta es la forma más sencilla para que los usuarios accedan a los metadatos sin necesidad de programación.
Aquí están algunos pasos para extraer metadatos de PDF:
Paso 1. Abre el PDF en Adobe Acrobat.
Paso 2. Accede a las Propiedades del Documento a través del menú Archivo.
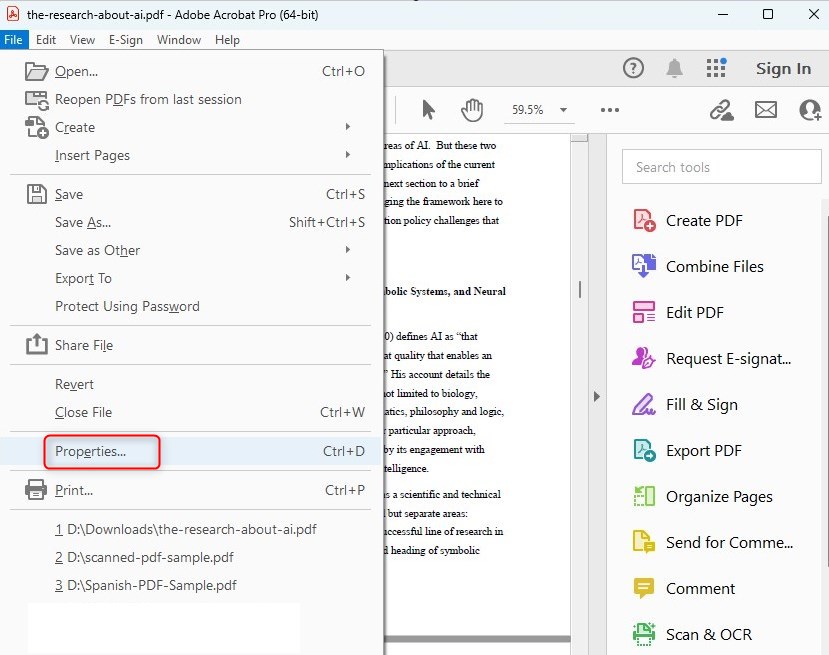
Abrir Propiedades del Documento en Adobe
Paso 3. Visualiza los metadatos en la pestaña Descripción, donde puedes ver campos como Título, Autor, Tema y Palabras clave.
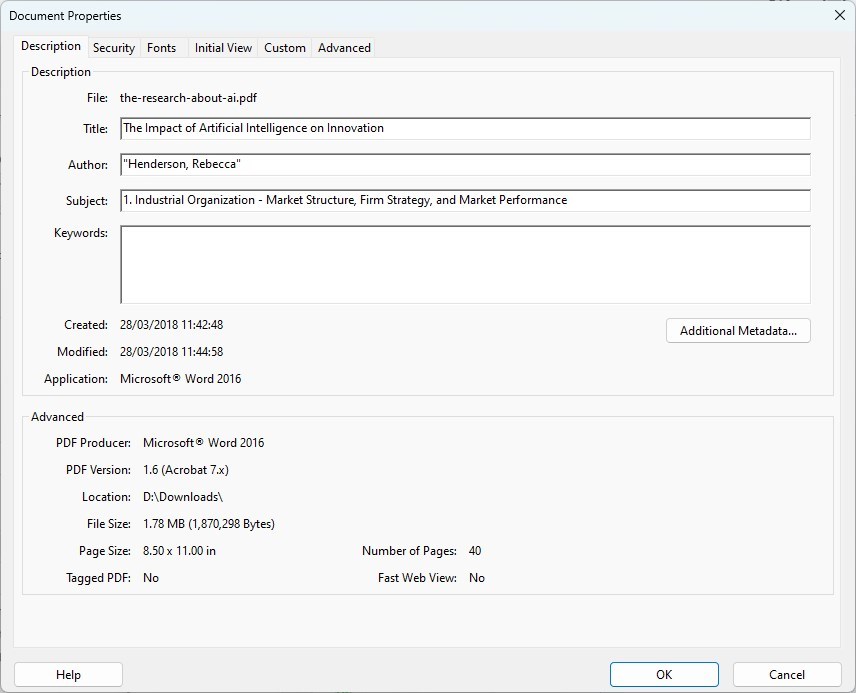
Ver los Metadatos del Archivo PDF
Paso 4. Extrae la información deseada seleccionando y copiando el texto.
Guarda los metadatos extraídos en un documento de texto o en una aplicación de notas para futuras referencias.
Extraer Páginas de un PDF
Para aquellos que necesitan extraer páginas específicas de un documento PDF existente para crear una versión nueva y más refinada del documento original. PDFgear ofrece una herramienta de división de PDF para dividir un archivo PDF por rangos de páginas o extraer todas las páginas de PDF en múltiples archivos PDF.
Aquí está cómo extraer páginas de un PDF y crear múltiples PDFs a partir de uno:
Paso 1. Primero, descarga e instala PDFgear en tu Windows o Mac. Inicia Adobe Acrobat DC en tu computador.
Abrir un PDF con PDFgear
Abre el archivo PDF del cual quieres extraer páginas haciendo clic en “Abrir Archivo” y seleccionando el documento PDF.
Paso 2. Una vez que tu PDF esté abierto, haz clic en la pestaña “Página” en la barra de menú superior.
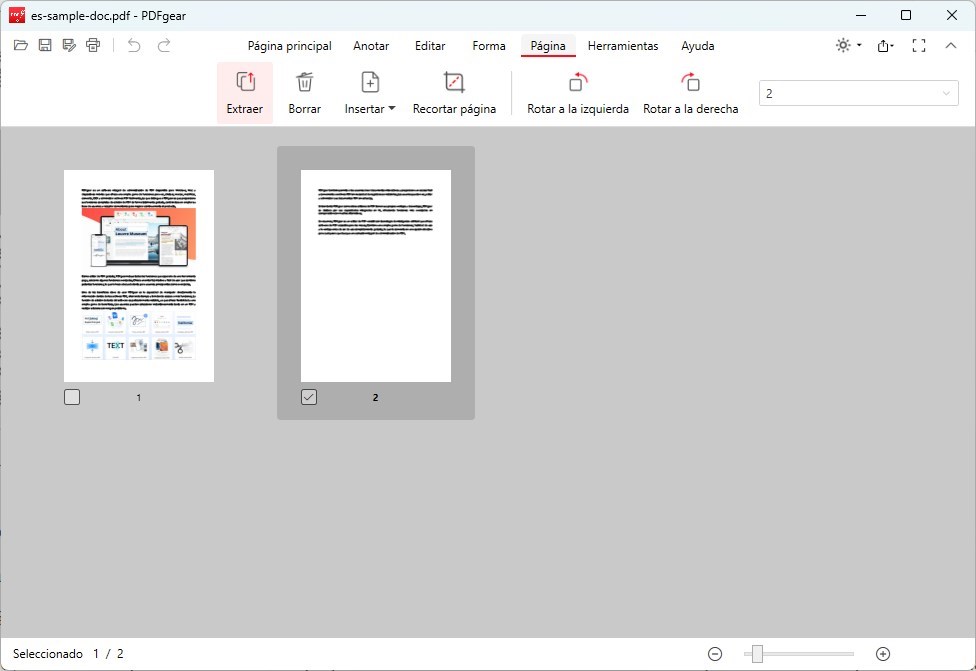
Opción de Extraer Página en PDFgear
Bajo la pestaña “Páginas“, verás opciones para manipular tus páginas de PDF, incluyendo su extracción.
Paso 3. Puedes seleccionar las páginas que deseas extraer. Puedes hacer clic en páginas individuales o seleccionar múltiples páginas.
Paso 4. Después de seleccionar las páginas, haz clic en el botón “Extraer” bajo la pestaña “Páginas“.
Aparecerá un nuevo cuadro de diálogo, dándote la opción de extraer las páginas seleccionadas como un archivo PDF separado. También puedes eliminar las páginas seleccionadas del documento original después de extraerlas marcando la opción “Eliminar páginas seleccionadas después de la extracción“.
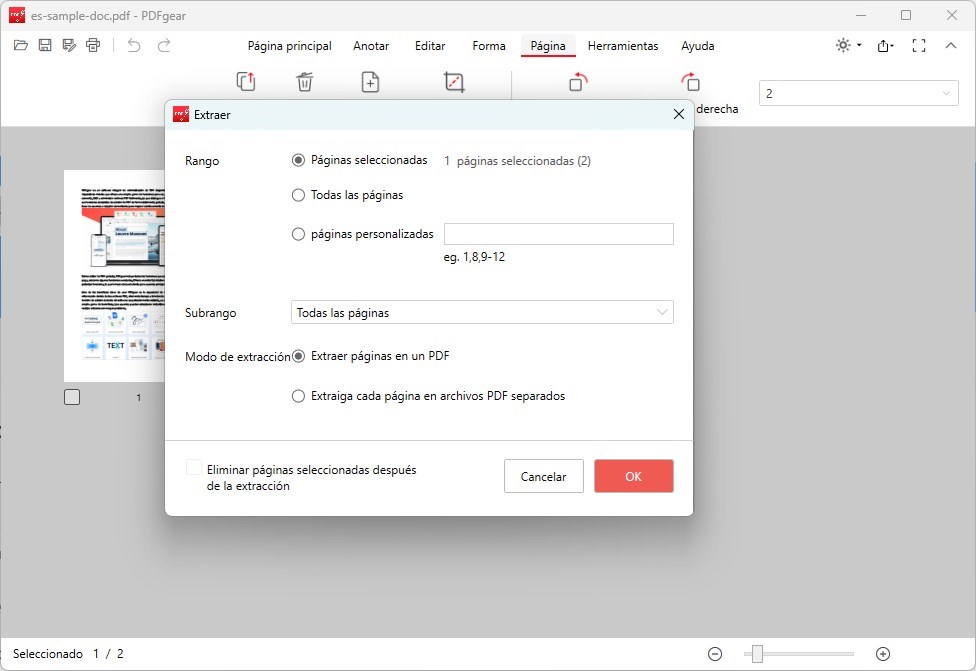
Extraer Páginas de un PDF con PDFgear
Haz clic en “OK” para extraer las páginas seleccionadas en un nuevo documento PDF.
Paso 5. Automáticamente pasarás al Explorador de Archivos. Desde allí, puedes elegir guardar las páginas de PDF extraídas en la ubicación deseada y especificar un nombre de archivo para el nuevo documento.
Extraer Imágenes de un PDF
Las imágenes incrustadas en los PDFs no están permanentemente fijas y pueden extraerse para usarse en otros lugares. Ya sea que necesites una imagen única o varias imágenes de un documento, puedes usar herramientas de software para extraerlas fácilmente.
Al usar un extractor de imágenes PDF, las imágenes se extraen en su formato y calidad originales. Y no se agregan marcas de agua a las imágenes extraídas.
Sigue estos pasos para extraer imágenes de un PDF en masa:
Paso 1. Abre tu navegador web y navega a la página de extracción de imágenes de PDF Candy.
Paso 2. Puedes subir el archivo PDF del que deseas extraer imágenes de varias maneras:
Simplemente arrastra el archivo PDF desde tu computadora y suéltalo en el área designada en la página web.

Añadir PDF al Extractor de Imágenes en Línea
Haz clic en el botón “ADD FILE” para abrir un cuadro de diálogo de archivo, luego navega y selecciona el archivo PDF que deseas usar.
Si tu PDF está almacenado en Google Drive o Dropbox, puedes subirlo directamente desde estos servicios haciendo clic en los iconos respectivos.
Paso 3. Una vez que hayas subido el PDF, PDF Candy comenzará automáticamente el proceso de extraer imágenes del documento PDF. No necesitas hacer nada durante este paso; la herramienta se encarga de todo.
Paso 4. Después de que el proceso de extracción esté completo, PDF Candy te proporcionará un archivo ZIP que contiene todas las imágenes extraídas del PDF.
Descargar las Imágenes Extraídas en Línea
Haz clic en el botón “Descargar” para guardar el archivo ZIP en tu computadora.
Si prefieres, también puedes guardar imágenes individuales al previsualizarlas y seleccionar específicas para descargar.
Preguntas más frecuentes
¿Cómo extraer información de un PDF usando Python?
Python tiene algunas bibliotecas para tratar con PDFs, como PyPDF2, PDFMiner y PyMuPDF. Puedes usarlas para obtener texto, información sobre el archivo y, a veces, incluso imágenes de los PDFs. La biblioteca que elijas depende de lo que necesites para tu proyecto, como si necesitas mantener el formato del texto detallado, extraer imágenes o asegurar que las cosas funcionen rápidamente.
¿Es posible extraer tablas de documentos PDF?
Sí, extraer tablas de documentos PDF se puede hacer usando herramientas como Tabula, Camelot y ExtractTable. Estas herramientas analizan la estructura del PDF e intentan reconocer y extraer datos tabulares en formatos como CSV o Excel, facilitando el trabajo con los datos.
¿Cómo extraer un resumen de un PDF con IA?
PDFgear tiene una herramienta de IA que puede ayudarte a resumir un PDF con facilidad. Abre un PDF en PDFgear después de descargar e instalar este software. Haz clic en el ícono del Copiloto para abrir la herramienta de IA. Envía el comando para pedirle al Copiloto que resuma tu PDF. Obtendrás un resumen en segundos.
Conclusión
Los PDFs almacenan valiosos textos, datos, metadatos, páginas e imágenes que pueden extraerse utilizando varios métodos, desde manuales hasta analizadores de IA automatizados. Los métodos mencionados en esta publicación proporcionan soluciones sencillas para extraer información de los PDFs para uso futuro.
PDFgear es uno de los mejores softwares de edición de IA. Proporciona diversas herramientas para extraer información como texto, páginas y resúmenes de los PDFs. Descárgalo para probar sus funciones y agilizar tu flujo de trabajo con PDFs.